Distributed systems form the backbone of many applications and services. From online shopping to social media, enterprise systems to emerging technologies like AR/VR and IoT, distributed systems are everywhere.
What is a Distributed System?
Leslie Lamport, a renowned computer scientist and Turing Award winner, defined a distributed system as "A distributed system is one in which the failure of a computer you didn't even know existed can render your own computer unusable."This definition highlights several key characteristics of distributed systems:
- Multiple independent components
- Possibility of component failures
- Collaboration and interaction between components
- Limited knowledge about other components
- Communication through explicit messages
A distributed system as a collection of independent, autonomous computing units that interact by exchanging messages and appear to external users as a single computing entity.
Why are Distributed Systems Hard?
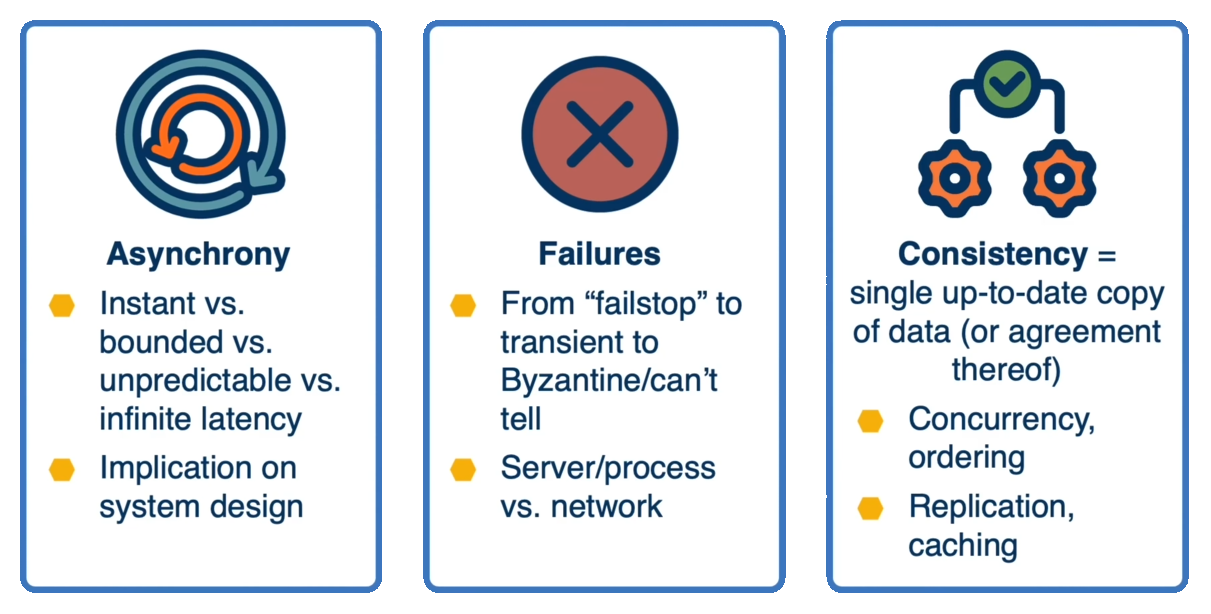
Several factors make distributed computing particularly challenging.Asynchrony
In real-world systems, message delivery times are often unpredictable (or at least non-zero) and potentially infinite. This asynchronous nature makes it difficult to reason about the order of events and the overall system state.
Failures
Distributed systems must contend with various types of failures:- Fail-stop failures (components simply stop working)
- Transient failures (temporary issues that resolve themselves)
- Byzantine failures (components behaving incorrectly or maliciously, communication errors, bugs in software, hardware faults)
Consistency
Maintaining a single, up-to-date copy of data across all nodes in the system is a significant challenge especially when considering factors like concurrency, replication, and caching.
Desirable Properties of Distributed Systems
Designing of a distributed system aims for several key properties:Consistency: In distributed systems, consistency refers to the property where all nodes in the system agree on and have access to the same data at the same time. It ensures that any read operation will return the most recent write operation's result, regardless of which node handles the request. Strong consistency models (like linearizability - an ordered list of invocation and response events) provide immediate consistency, while weaker models (like eventual consistency) may allow temporary inconsistencies but guarantee convergence over time.
High Availability is the ability of a distributed system to remain operational and responsive for a high percentage of time - despite failures of individual components. This often involves/implies redundancy, load balancing, and quick failure detection and recovery mechanisms. The goal is to minimize downtime and ensure that the system can continue to provide services even when some parts of it fail.
Partition Tolerance is the capability of a distributed system to continue functioning when network failures cause the system to split into separate groups that can not communicate with each other (network partitions). A partition-tolerant system can maintain its core functionality and consistency guarantees even when messages between nodes are lost or delayed due to network issues.
Fault Tolerance is the ability of a distributed system to continue operating correctly even when one or more of its components fail. This involves detecting failures, containing their impact, and recovering from them without interrupting the entire system's operation. Fault-tolerant systems often use techniques like replication, checkpointing, and redundancy to maintain functionality in the face of failures.
Recoverability refers to the ability of a distributed system to return to a correct state and resume normal operations after experiencing a failure. This includes mechanisms for data recovery, state reconstruction, and bringing failed components back online without corrupting the system's overall state or violating consistency guarantees.
Scalability is the capability of a distributed system to handle increased load or grow in size without significant degradation in performance or reliability. This can involve horizontal scaling (adding more nodes) or vertical scaling (increasing the capacity of existing nodes). A scalable system should be able to maintain its performance and reliability as it grows to accommodate more users, data, or transactions.
Predictable Performance in distributed systems means that the system consistently meets specified performance targets (like response time or throughput) under varying conditions. This involves designing the system to handle expected load variations, ensuring consistent resource allocation, and implementing mechanisms to prevent performance degradation due to factors like network latency or component failures.
Security: In the context of distributed systems, security encompasses various aspects of protecting the system from unauthorized access, data breaches, and malicious attacks. This includes:
- Authentication: Verifying the identity of users and system components.
- Authorization: Controlling access to resources based on verified identities.
- Data encryption: Protecting data both in transit and at rest.
- Integrity: Ensuring that data and system states have not been tampered with.
- Non-repudiation: Providing proof of the integrity and origin of data.
- Auditing: Keeping records of system activities for security analysis.
The CAP Theorem

The CAP theorem, proposed by Eric Brewer, states that a distributed system cannot simultaneously guarantee all three of the following properties in the event of a network partition:
-
Consistency - the guarantee that all nodes in the system have the same view of the data at any
given time
- Strong Consistency ensures that all nodes see the same data at the same time. Any read operation will return the most recent write. This model provides the highest level of consistency but can impact performance and availability.
- Sequential Consistency ensures that the results of execution are the same as if the operations were executed in some sequential order. All processes see the operations in the same order, but not necessarily the most recent write.
- Eventual Consistency guarantees that, given enough time, all nodes will converge to the same value. This model is often used in systems where high availability is more critical than immediate consistency.
- Causal Consistency ensures that causally related operations are seen by all nodes in the same order. Operations that are not causally related may be seen in different orders by different nodes.
- Availability refers to the system's ability to remain operational and accessible when needed
- Partition tolerance refers to the system's ability to continue operating correctly even when there are communication breakdowns or network partitions between nodes.
Key Concepts
A Distributed System is a collection of independent, autonomous computing units that interact by exchanging messages and appear to external users as a single coherent computing entity.
Asynchrony is the property of a system where message delivery times are unpredictable and potentially infinite, making it difficult to reason about the order of events and overall system state.
Consistency is the property of a distributed system where all nodes agree on the current state of the system and see the same data at the same time.
Availability is the ability of a distributed system to remain operational and provide responses to requests, regardless of failures or delays in individual components.
Partition Tolerance is the capability of a distributed system to continue functioning when network partitions occur (e.g., when communication between some nodes in the system is lost).
The CAP Theorem is a principle stating that a distributed system cannot simultaneously guarantee Consistency, Availability, and Partition tolerance in the event of a network partition.
Fault Tolerance is the ability of a system to continue operating correctly even when some of its components fail.
Scalability The capability of a system to handle increased load or grow in size without significant degradation in performance or reliability.
A Byzantine Failure is a type of failure in which a component of the system fails in arbitrary ways, potentially behaving maliciously or sending incorrect information to other parts of the system.
Linearizability is a consistency model that ensures that operations (or groups of operations) on shared state appear to execute instantaneously at some point between their invocation and completion.
Serializability is a consistency model that ensures that the execution of concurrent operations (or transactions) is equivalent to some sequential execution of those operations.
Linearizability
- Definition: Linearizability, also known as atomic consistency, ensures that all operations appear to occur instantaneously at some point between their invocation and their response.
- Key Characteristics:
- Real-time Order: Operations are ordered based on real-time. If one operation completes before another starts, the system must reflect this order.
- Single Operation Focus: It applies to individual operations on a single object.
- User Perspective: From the user's perspective, once an operation is acknowledged, its effects are visible to all subsequent operations.
- Definition: Serializability ensures that the outcome of executing transactions concurrently is the same as if the transactions were executed serially, one after the other.
- Key Characteristics:
- Transaction Focus: It applies to transactions, which can include multiple operations on multiple objects.
- No Real-time Constraints: It does not require operations to be ordered based on real-time. Instead, it focuses on the logical order of transactions.
- Isolation: Transactions are isolated from each other, ensuring that intermediate states are not visible to other transactions.
- Scope:
- Linearizability: Applies to individual operations on single objects.
- Serializability: Applies to entire transactions, which can involve multiple operations on multiple objects.
- Order:
- Linearizability: Requires real-time order of operations.
- Serializability: Requires logical order of transactions, without real-time constraints.
- Use Cases:
- Linearizability: Suitable for systems where real-time consistency is crucial, such as distributed databases and shared memory systems.
- Serializability: Suitable for transactional systems like databases where the correctness of transactions is more important than real-time order.
In Distributed Systems, a model is a simplified representation of a distributed system used for analysis and design, typically including system elements (e.g., nodes, channels) and rules governing their behavior.
A Node is an individual computing unit in a distributed system, capable of performing local computations and sending/receiving messages.
A Channel is a communication link between nodes in a distributed system model, used for sending and receiving messages.
Message Passing is the primary method of communication in distributed systems, where nodes exchange information by sending discrete messages to each other.
State is the current condition or values of variables in a node or the entire distributed system at a given point in time.
Latency is the time delay between the initiation of a request or action and the receipt of a response in a distributed system.
Replication is the process of maintaining multiple copies of data or services across different nodes in a distributed system to improve reliability and performance.
Consensus is the process by which nodes in a distributed system agree on a common value or decision, despite the possibility of failures or Byzantine behavior.
Eventual Consistency is a weak consistency model that guarantees that, given enough time without updates, all replicas in a distributed system will converge to the same state.
Sharding is the practice of horizontally partitioning data across multiple nodes in a distributed system to improve scalability and performance.
Load Balancing is the distribution of workloads across multiple nodes in a distributed system to optimize resource utilization and improve overall system performance.
Review questions
What are defining characteristics of a distributed system?
- Collection of independent, autonomous computing units
- Interact by exchanging messages via an interconnection network
- Appear to external users as a single coherent computing facility
- Can be affected by failures of components unknown to other parts of the system
What are some simple models to represent a Distributed System?
- Nodes and messages exchanged between them
- (More complex model) nodes with state, and messages that can change that state
Why would you choose to use a system model?
- They allow us to reason about system behavior without building prototypes
- Enable making strong statements about system behavior
- Allow for both theoretical advances and practical implementation
Using a simple model, can you describe how
Using a simple model, we can describe how nodes interact through messages, how failures might occur, and how the system state changes over time.
What do we mean by asynchronous?
Asynchrony in distributed systems means that message delivery is unpredictable and potentially has infinite latency.
What about asynchrony makes distributed computing hard?
- It is difficult to determine if a message was lost or just delayed
- Complicates coordination between nodes
- Makes it challenging to establish a consistent view of the system state
What about failures makes distributed computing hard?
- There are various types of failures (fail-stop, transient, Byzantine)
- It is difficult to determine if a component has failed or is just slow
- Failures can affect individual servers, processes, or network links
- The system must continue to function correctly despite failures
Why is consistency a hard problem in distributed computing?
- It requires maintaining a single, up-to-date copy of data or state across all nodes
- Nodes must agree on this state despite potential failures, delays, or network partitions
- It involves considering factors like concurrency, ordering of operations, data replication, and caching
- There are trade-offs between consistency, availability, and partition tolerance (CAP theorem)
Explain why "The network is reliable" fallacy is not true and how does it make distributed computing more challenging?
This fallacy is not true because networks can and do fail in various ways (e.g., packet loss, disconnections, corruptions). This makes distributed computing more challenging because:
- Systems must be designed to handle network failures
- It complicates maintaining consistency across nodes
- It affects the ability to guarantee message delivery and ordering
What does "The system gives correct answers always, regardless of failures" mean?
- The system should maintain consistency even in the presence of failures
- It should be fault-tolerant and able to recover from component failures
- The system should continue to operate correctly despite network partitions or node failures
What does it mean with respect to the required properties of the system?
- It implies that the system should have mechanisms in place to handle various failure scenarios while still providing correct results
How does consideration of Latency relate to the observations made by CAP?
- While CAP focuses on consistency vs. availability in the presence of network partitions
- Latency considerations introduce a trade-off between response time and consistency
- In some applications, a slow answer is equivalent to no answer (unavailability)
- Systems may need to choose between providing a fast response based on potentially outdated local data or waiting for the most up-to-date information, which may introduce higher latency