In the ever-expanding world of big data, the need for efficient and scalable data processing frameworks has never been greater.
The MapReduce Revolution
MapReduce, introduced by Google in a 2004 paper, revolutionized big data processing. This programming model and implementation allowed for the processing of vast amounts of data across large clusters of commodity hardware. The key features of MapReduce include:
- Data Parallelism: Input data is divided into chunks and processed independently.
- Pipelining: Processing is divided into map and reduce phases, allowing for efficient data flow.
- Fault Tolerance: The system can handle node failures and data loss through replication and re-execution.
However, MapReduce had its limitations, primarily due to its heavy reliance on disk I/O for intermediate results, which could lead to performance bottlenecks in iterative algorithms.
Enter Apache Spark
To address the limitations of MapReduce, Apache Spark was developed at UC Berkeley. Spark introduced several key innovations:
- Resilient Distributed Datasets (RDDs): The core abstraction in Spark, RDDs are immutable, distributed collections of objects that can be processed in parallel (ref).
- In-Memory Processing: Spark keeps data in memory between operations, significantly reducing I/O overhead.
- Lazy Evaluation: Transformations on RDDs are not executed until an action is called, allowing for optimization of the execution plan.
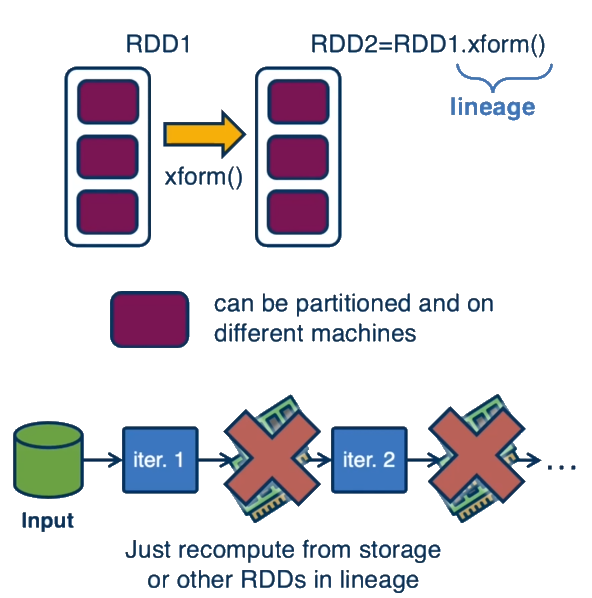
- Lineage Tracking: Spark maintains the lineage of transformations, enabling efficient fault recovery without extensive data replication.
Key Differences and Advantages
- Performance: Spark can be up to 100 times faster than Hadoop MapReduce for certain workloads, especially for iterative algorithms and interactive data analysis.
- Ease of Use: Spark offers rich APIs in multiple languages (Scala, Java, Python, R) and supports various data processing paradigms (batch, interactive, streaming, machine learning).
- Versatility: While MapReduce is primarily designed for batch processing, Spark can handle batch, interactive, and streaming workloads in the same engine.
- Fault Tolerance: Both systems offer fault tolerance, but Spark's approach using RDD lineage can lead to faster recovery in many scenarios.
Real-World Impact
The introduction of Spark has enabled new classes of applications and significantly improved the performance of existing big data workflows. For example, the PageRank algorithm, when implemented in Spark, can run up to 10 times faster than its Hadoop MapReduce counterpart.
The evolution from MapReduce to Spark represents a significant leap forward in distributed data processing. While MapReduce laid the groundwork for large-scale data processing, Spark has built upon this foundation to offer a more flexible, efficient, and user-friendly framework. As data continues to grow in volume and complexity, frameworks like Spark will play an increasingly crucial role in helping organizations extract valuable insights from their data assets.
Key Concepts
Distributed Systems: Computer systems in which components located on networked computers communicate and coordinate their actions by passing messages.
Big Data: Extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations.
Data Parallel Approach: A method of parallelization where data is divided into subsets, each processed independently on different nodes.
Pipelining: Dividing a task into a series of subtasks, each performed by a specialized unit, allowing for simultaneous processing of multiple data items.
Fault Tolerance: The ability of a system to continue operating properly in the event of the failure of some of its components.
Data Streaming: Processing of data in motion, or real-time data processing.
Machine Learning Pipeline: A series of data processing steps coupled with machine learning algorithms, often implemented using frameworks like Spark MLlib.
Graph Processing: Algorithms and systems designed to process large-scale graphs, such as social networks or web graphs.
Interactive Analytics: The ability to query and analyze data in real-time, often through SQL-like interfaces provided by systems like Spark SQL.
Resource Management: Systems like YARN (Yet Another Resource Negotiator) that manage and allocate resources in a distributed computing environment.
MapReduce Concepts
MapReduce: A programming model and implementation for processing and generating big data sets with a parallel, distributed algorithm on a cluster.
Mapper: The function in MapReduce that performs filtering and sorting of input data.
Reducer: The function in MapReduce that performs a summary operation on the output of the Mapper.
Key-Value Pairs: The data structure used in MapReduce for input and output of the Map and Reduce functions.
Hadoop: An open-source framework that implements the MapReduce model for distributed storage and processing of big data sets.
Apache Spark Concepts
Apache Spark: An open-source, distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance.
Resilient Distributed Datasets (RDDs): The fundamental data structure of Spark. An RDD is an immutable, partitioned collection of elements that can be operated on in parallel.
Transformations: Operations on RDDs that create a new RDD from an existing one. Examples include map, filter, and join.
Actions: Operations that return a value to the driver program or write data to an external storage system. Examples include count, collect, and save.
Lazy Evaluation: The strategy used by Spark where the execution of transformations is delayed until an action is called.
Lineage: The sequence of transformations that created an RDD, used by Spark for fault recovery.
In-Memory Processing: Spark's ability to keep data in RAM between operations, significantly reducing I/O overhead compared to disk-based systems like Hadoop MapReduce.
Spark Driver: The process running the main() function of the application and creating the SparkContext.
Spark Executor: Worker processes responsible for running individual tasks in a Spark job.
Directed Acyclic Graph (DAG): The execution plan of Spark jobs, representing the sequence of operations to be performed on the data.
Review Questions
What are the different strategies how you can scale data analytics to larger input sizes and to larger processing complexity? What are the fundamental tradeoffs that they introduce?
There are several key strategies for scaling data analytics to handle larger data volumes and more complex processing:
-
Data Parallelism: Dividing the data into smaller chunks that can be processed in parallel by different nodes in a system. This approach assumes that good load balancing can be achieved when partitioning the data.
-
Pipelining: Breaking down complex computations into smaller tasks and having specialized nodes handle specific parts of the pipeline. This allows for higher throughput as data can be streamed through the system.
-
Model Parallelism: Distributing the application state or model across multiple nodes, with each node handling a portion of the state.
These strategies introduce several fundamental tradeoffs:
- Locality vs. Communication: Processing data where it's stored reduces network traffic but may lead to under-utilization of compute resources.
- Fault Tolerance vs. Performance: Ensuring the system can recover from failures often requires additional overhead like data replication or check-pointing.
- Simplicity vs. Flexibility: More general systems tend to be harder to optimize for specific workloads.
- Latency vs. Throughput: Systems optimized for high throughput often sacrifice latency and vice versa.
- Memory Usage vs. Disk I/O: In-memory processing is faster but more expensive and has capacity limitations.
How are these strategies combined in the original design of MapReduce presented by Google?
The original MapReduce design combines these strategies in several ways:
-
Data Parallelism: Input data is split into chunks (typically 16-64MB), and map tasks process these chunks in parallel across many machines.
-
Functional Decomposition: The computation is divided into map and reduce phases, creating a simple two-stage pipeline.
-
Locality Optimization: The MapReduce scheduler attempts to assign map tasks to machines that have the input data locally available, reducing network traffic.
-
Fault Tolerance: MapReduce handles machine failures by re-executing failed tasks on other machines. It also uses "backup tasks" to mitigate the effect of stragglers (abnormally slow machines).
-
Intermediate Data Management: Map tasks write intermediate results to local disk, which are then fetched by reduce tasks, providing a checkpoint for fault recovery.
These design choices prioritize fault tolerance, scalability, and simplicity over latency and fine-grained control.
What is the goal of using intermediate files to store results from each operation in a MapReduce pipeline? What are the pros and cons of this decision?
The goal of using intermediate files in MapReduce is primarily to enable fault tolerance and simplify the programming model.
Pros:
- Fault Tolerance: If a reduce task fails, it can be restarted without re-executing the map tasks since their outputs are stored on disk.
- Simplified Programming Model: Developers don't need to worry about complex distributed system issues like communication protocols or synchronization.
- Handling Data Skew: The system can handle uneven distribution of data by redistributing intermediate results.
- Checkpoint Recovery: Intermediate files serve as natural checkpoints in the computation pipeline.
Cons:
- I/O Overhead: Writing and reading from disk introduces significant latency and can become a bottleneck.
- Serialization Cost: Data must be serialized when written to disk and deserialized when read, adding processing overhead.
- Network Bandwidth Consumption: Shuffling data between map and reduce phases can consume substantial network resources.
- Limited Pipeline Flexibility: The rigid map-shuffle-reduce pattern limits the types of computations that can be expressed efficiently.
- Iterative Algorithm Inefficiency: For iterative algorithms, reading and writing data for each iteration creates substantial overhead.
How are these problems addressed by Spark? What is the key idea in Spark?
Spark addresses the limitations of MapReduce through its key abstraction: Resilient Distributed Datasets (RDDs).
The key idea in Spark is to keep data in memory across operations rather than writing intermediate results to disk. RDDs are immutable, distributed collections of data that can be stored in memory across operations, eliminating the need to read from and write to disk between steps.
Spark addresses MapReduce's problems through:
-
In-Memory Processing: By keeping data in memory between operations, Spark dramatically reduces I/O overhead, particularly beneficial for iterative algorithms.
-
Rich Set of Operations: Beyond just map and reduce, Spark offers a comprehensive set of transformations and actions, making it more expressive.
-
Lazy Evaluation: Transformations on RDDs are not executed immediately but are recorded as part of a lineage graph, allowing Spark to optimize the execution plan.
-
Lineage-Based Recovery: Instead of checkpointing all intermediate data, Spark tracks how each RDD was derived and can recompute only the lost partitions if needed.
-
Flexible Execution Model: Spark supports batch processing, interactive queries, streaming data, and machine learning in a unified programming model.
How do RDDs and lineage speed up processing of analytics applications?
RDDs and lineage speed up analytics applications in several ways:
-
In-Memory Computation: RDDs can be persisted in memory, eliminating costly disk I/O operations between stages of a multi-step pipeline.
-
Reduced Serialization: Since data stays in memory as Java objects, Spark avoids repeated serialization and deserialization costs.
-
Pipeline Optimization: The lineage graph allows Spark to combine multiple operations into a single stage when possible (known as pipelining), reducing overhead.
-
Intelligent Caching: Users can explicitly control which RDDs to cache in memory based on their reuse patterns, optimizing memory usage.
-
Locality-Aware Scheduling: Spark's scheduler uses lineage information to place computations close to the data they operate on.
-
Efficient Iteration Support: For iterative algorithms (like machine learning), data can be cached once and reused across iterations, providing orders of magnitude speed improvement over MapReduce (ref).
The lecture transcription shows that Spark achieved 2-9x improvements over Hadoop for the PageRank algorithm, primarily due to avoiding I/O and keeping data in memory.
How do RDDs and lineage provide support for fault-tolerance?
RDDs and lineage provide an elegant approach to fault tolerance:
-
Lineage Tracking: Each RDD keeps track of its parent RDDs and the transformations that were applied to create it. This lineage graph is a compact representation of the computation.
-
Deterministic Recomputation: If an RDD partition is lost due to a machine failure, Spark can rebuild just that partition by reapplying the sequence of transformations from the lineage graph, starting from the original data.
-
Fine-Grained Recovery: Unlike MapReduce, which typically needs to restart entire map or reduce tasks, Spark can recover just the lost RDD partitions.
-
Memory Pressure Handling: If there's insufficient memory, Spark can spill RDDs to disk or recompute them when needed, gracefully degrading performance rather than failing.
-
Narrow vs. Wide Dependencies: Spark distinguishes between transformations with narrow dependencies (where each partition of the parent RDD affects at most one partition of the child RDD) and wide dependencies (where multiple child partitions may depend on one parent partition). This distinction helps optimize recovery - narrow transformations can be recovered in parallel, while wide ones may require more coordination.
The papers show that this approach allows Spark to recover quickly from failures by rebuilding only the lost partitions and continuing execution, rather than restarting entire computations.
Understand the Spark log mining example: what are the different constructs, what is their purpose, how are they used?
The Spark log mining example demonstrates several key Spark constructs:
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
-
RDD Creation (lines): The
textFilemethod creates an RDD from a file in HDFS, with each line as an element. -
Transformation (filter): The
filtertransformation creates a new RDD (errors) containing only lines that start with "ERROR". -
Persistence (persist): The
persist()method tells Spark to keep theerrorsRDD in memory for future operations, as it will be reused across multiple queries.
errors.count()
errors.filter(_.contains("MySQL")).count()
errors.filter(_.contains("HDFS"))
.map(_.split('\t')(3))
.collect()
-
Actions (count, collect): These trigger actual computation.
count()returns the number of elements, andcollect()returns all elements to the driver. -
Chained Transformations: Multiple transformations can be chained together before an action is performed. In the third example, Spark filters lines containing "HDFS", then extracts the fourth field (index 3) from each line by splitting on tab characters.
-
Lazy Evaluation: No computation happens until an action (
count()orcollect()) is called. This allows Spark to optimize the execution plan.
The example shows how Spark allows interactive data exploration. After loading and filtering the data once, multiple queries can be run efficiently since the filtered data is cached in memory. The lineage graph shown in Figure 1 illustrates how Spark tracks the relationships between RDDs, enabling both optimization and fault recovery.
How does the information about or embedded in RDDs help with placement and scheduling?
Information embedded in RDDs helps with placement and scheduling in several ways:
-
Partitioning Information: RDDs know how they are partitioned, which allows Spark to schedule tasks that preserve data locality and minimize data movement. For instance, in the PageRank example, partitioning the links and ranks RDDs consistently ensures that joins can be performed without shuffling data.
-
Preferred Locations: RDDs can specify "preferred locations" for computing each partition, typically based on data locality. This allows the scheduler to place tasks on nodes where the data is already stored.
-
Dependency Information: RDDs maintain information about their dependencies (narrow or wide), which helps the scheduler determine how to stage computations. Operations with narrow dependencies can be pipelined into a single stage, while wide dependencies require data shuffling.
-
Lineage Graph: The complete lineage graph allows the scheduler to understand the full computational path, enabling global optimization of task placement and execution order.
-
Custom Partitioners: Users can specify custom partitioning schemes (e.g., hash partitioning by URL in the PageRank example), allowing application-specific optimizations for data placement.
-
Fault Recovery Information: The lineage information enables the scheduler to efficiently recover from failures by knowing exactly which partitions need to be recomputed and where.
This rich metadata about data location, dependencies, and computation history allows Spark to make intelligent scheduling decisions that minimize data movement, optimize resource utilization, and recover efficiently from failures - all while hiding these complexities from the application developer.