In recent years, machine learning (ML) has revolutionized numerous industries, from healthcare to recommendation systems and scientific discovery. As ML applications become increasingly global, systems will process vast amounts of data generated at the edges of networks.
As machine learning continues to evolve and expand globally, the need for efficient geo-distributed ML solutions becomes increasingly critical. Systems like Gaia and Cartel represent significant steps forward in addressing the unique challenges of geo-distributed machine learning. By leveraging approximation, collaborative learning, and innovative synchronization methods.
The Challenge of Geo-Distributed Machine Learning
Traditional ML approaches often rely on centralized data processing in data centers. However, with the proliferation of IoT devices, smartphones, and sensors worldwide, much of the data is generated far from these centralized locations. This presents two main challenges:
- Data Movement: Transferring large amounts of data from distributed locations to centralized data centers is expensive and time-consuming.
- Data Sovereignty: Moving data across international boundaries can raise legal and privacy concerns.
Approaches to Distributed Machine Learning
Centralized Approach
The simplest model involves collecting all data from various locations to a single centralized place for analysis. However, this approach can be up to 53 times slower than local processing due to data movement overhead.
Federated Learning
Federated learning approaches, like Google's Federated Averaging, perform local learning at distributed locations and periodically aggregate model updates centrally. This reduces data movement but still aims for a global model.
Parameter Server Architecture
Systems like Parameter Server (OSDI 2014) distribute training data and model parameters across worker machines and parameter servers. While effective in data centers, this approach can be over 20 times slower when deployed across geo-distributed locations.
Innovative Solutions
Gaia: Leveraging Approximation
Gaia, introduced at ATC, tackles the challenges of geo-distributed ML by:
- Decoupling synchronization within data centers from synchronization among data centers.
- Using an Approximate Synchronous Parallel (ASP) model to communicate only significant updates across data centers.
- Implementing mechanisms like significance filtering and ASP barriers to manage synchronization.
Gaia achieves performance close to that of localized learning in a single data center, significantly improving upon naive geo-distributed implementations.
Cartel: Collaborative Learning
Cartel, developed by researchers and published at the Cloud Computing Symposium in 2019, introduces a collaborative learning approach:
- Allows each node to maintain a small, customized model.
- Enables knowledge transfer between nodes when environmental changes occur.
- Uses a metadata service to find suitable peers for knowledge transfer.
Cartel shows promising results, including faster model convergence, reduced data transfer, and more lightweight models compared to centralized approaches.
Trade-offs and Considerations
While global models (as pursued by Gaia and federated learning) offer uniformity, they may not always be necessary or optimal. Local data trends can often be better served by smaller, tailored models. The challenge lies in balancing the benefits of local optimization with the advantages of shared knowledge.
Beyond Training: The ML Pipeline
It is important to note that training is just one part of the machine learning pipeline. Systems like Ray (OSDI 2018) aim to integrate various components of the ML pipeline, including model serving, data delivery, and distributed tensor manipulations, into a unified framework.
Key Concepts
Distributed Machine Learning: The practice of performing machine learning tasks across multiple interconnected computers or devices, often geographically dispersed.
Geo-Distributed Systems: Computing systems or networks that span multiple geographic locations, often across countries or continents.
Data Center: A facility used to house computer systems and associated components, such as telecommunications and storage systems.
Edge Computing: A distributed computing paradigm that brings computation and data storage closer to the location where it is needed, often at the "edge" of the network.
Data Sovereignty: The concept that data is subject to the laws and governance structures within the nation it is collected.
Federated Learning: A machine learning technique that trains algorithms on decentralized devices or servers holding local data samples, without exchanging them.
Parameter Server: A distributed system architecture where parameters of a machine learning model are stored on dedicated servers, while computation is performed on separate worker nodes.
Gaia: A system for efficient machine learning in geo-distributed settings that leverages approximate computing techniques.
Approximate Synchronous Parallel (ASP): A synchronization model used in Gaia that relaxes consistency requirements to improve efficiency in geo-distributed settings.
Cartel: A system that enables collaborative learning in decentralized environments, allowing nodes to maintain local models while benefiting from knowledge transfer.
Collaborative Learning: An approach where multiple decentralized entities contribute to training machine learning models while keeping data locally.
Model Drift: The degradation of a model's performance over time as the statistical properties of the target variable change.
Knowledge Transfer: The process of applying knowledge from one domain or task to another, often used in machine learning to improve model performance with limited data.
Centralized Learning: An approach where all data is collected and processed in a single, central location.
Isolated Learning: An approach where each node in a distributed system learns independently, without sharing data or model updates.
Global Model: A single, unified machine learning model that is used across an entire system, regardless of location.
Local Model: A machine learning model tailored to the specific data and patterns of a particular location or subset of a larger system.
Model Serving: The process of making a trained machine learning model available for use in making predictions or classifications.
Inference: The process of using a trained machine learning model to make predictions or classifications on new, unseen data.
Machine Learning Pipeline: The end-to-end process of building and deploying machine learning models, including data collection, preprocessing, model training, evaluation, and deployment.
Ray: A unified framework for scaling AI and Python applications, integrating various components of the machine learning pipeline.
Review Questions
Contrast Federated Learning to a more naïve centralized learning approach
Federated Learning differs from the naïve centralized learning approach in several key ways:
In the centralized approach, all raw data from distributed sources is moved to a single data center before running any machine learning algorithm. This creates several issues:
- Moving large amounts of raw data over WANs is extremely slow
- Privacy and data sovereignty laws may prohibit raw data transfer across national borders
- It creates a bottleneck due to limited WAN bandwidth
In contrast, Federated Learning:
- Keeps all training data on local devices (phones, edge servers, etc.)
- Trains local models on each device using local data
- Only shares model updates (not raw data) with a central server
- Updates are aggregated centrally to improve a shared global model
- The improved model is then distributed back to devices
As described in the Google Research article, in Federated Learning, "your device downloads the current model, improves it by learning from data on your phone, and then summarizes the changes as a small focused update. Only this update to the model is sent to the cloud, using encrypted communication, where it is immediately averaged with other user updates to improve the shared model."
This approach provides benefits of:
- Privacy preservation as raw data never leaves the device
- Reduced network traffic (only model updates are transmitted)
- Personalization of models locally based on device usage
- Compliance with data sovereignty laws
Explain the role of Parameter Server in the distributed machine learning system
The Parameter Server (PS) architecture is a key infrastructure design for distributed machine learning systems that allows for effective parallelization across multiple machines. Its role includes:
-
Distributed Global Shared Memory: It provides worker machines with a distributed global shared memory abstraction for ML model parameters they collectively train.
-
Key-Value Store: Each parameter server keeps a shard of the global model parameters as a key-value store, with different servers handling different parts of the model.
-
Synchronization Management: The parameter server handles synchronization between workers, determining when and how model updates should be propagated.
-
Communication Coordination: It manages communication between workers and servers to enable efficient READ and UPDATE operations on the model parameters.
-
Iteration Management: The parameter server ensures that the learning process proceeds in an iterative manner where:
- Workers get parameters
- Compute updates based on their local data shards
- Communicate updated parameters to servers
- Servers aggregate information, synchronize amongst themselves
- Determine model updates
- Propagate back to workers for the next iteration
The parameter server architecture enables efficient training of machine learning models across multiple machines within a data center, allowing the system to leverage parallel processing of large datasets while maintaining model consistency.
What are the problems with naively scaling a system such as Parameter Server, designed for a single datacenter, to a geo-distributed setting?
Naively scaling a Parameter Server system designed for a single data center to a geo-distributed setting creates several significant problems:
-
Extreme Performance Degradation:
- Experiments showed Parameter Server systems were 3-53.7× slower when deployed across data centers compared to within a data center
- Even with just two data centers, significant slowdowns occurred
-
WAN Bandwidth Limitations:
- WAN bandwidth is 15-60× smaller than LAN bandwidth
- WAN bandwidth varies significantly between different regions (up to 12× difference)
- Parameter servers require extensive communication which overwhelms limited WAN bandwidth
-
WAN Latency and Heterogeneity:
- Higher latency between data centers disrupts the frequent synchronization needed
- Heterogeneous bandwidth between different regions creates imbalanced performance
-
Communication Overhead:
- Parameter server architecture requires frequent synchronization of model parameters
- This synchronization becomes extremely costly over WANs
- The cost of data transfer on WANs is much higher than within a data center (up to 38× the cost of the machines themselves)
-
Staleness and Consistency Issues:
- Slower communication makes it difficult to maintain consistency of model copies
- Parameter server designs assume low-latency, high-throughput connections to training data
-
Data Sovereignty Concerns:
- Moving data across international boundaries may violate privacy and data sovereignty laws
Even when using more communication-efficient models like Stale Synchronous Parallel (SSP), the performance degradation remains substantial in geo-distributed settings due to these fundamental network limitations.
How does Gaia address these problems? What are the main components of the system?
Gaia addresses the problems of geo-distributed machine learning through several innovative approaches:
Key Approach:
Gaia decouples the synchronization within a data center (LANs) from the synchronization between different data centers (WANs), enabling different communication and consistency models for each.
Main Components:
-
Differentiated Synchronization Model:
- Within each data center: Uses conventional synchronization models (BSP or SSP) to maximize LAN bandwidth utilization
- Between data centers: Uses a new model called Approximate Synchronous Parallel (ASP) to efficiently use scarce WAN bandwidth
-
Globally Distributed Parameter Servers:
- Parameter servers in each data center maintain an approximately-correct copy of the global ML model
- Workers in each data center only communicate with local parameter servers
-
Significance Filter:
- Determines which updates are significant enough to share across data centers
- Takes a significance function and threshold as input
- Dynamically reduces threshold over time to ensure convergence
- Filters out insignificant updates (95-99% of all updates) to reduce WAN communication
-
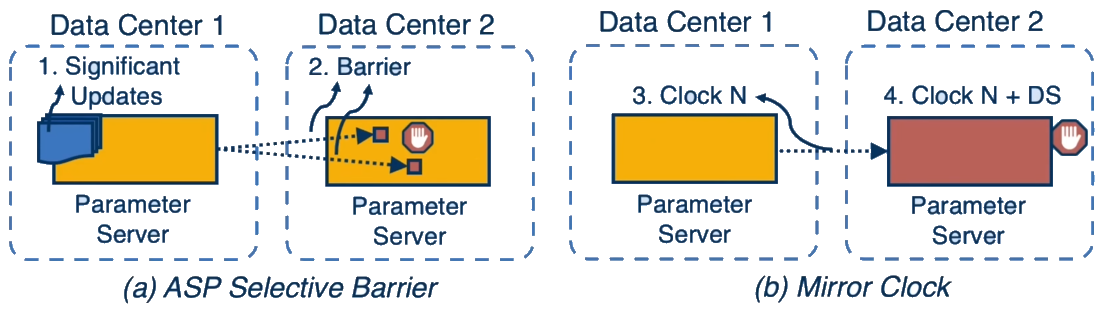
ASP Selective Barrier:
- Control mechanism that first sends indexes of significant updates before sending the actual values
- Blocks worker machines from reading specific parameters until significant updates arrive
- Ensures workers are aware of significant updates in a timely manner
-
Mirror Clock:
- Monitors clock differences between parameter servers across data centers
- Blocks local worker machines if a server gets too far ahead of others
- Ensures algorithm convergence even with WAN bandwidth fluctuations
- Acts as a last resort to guarantee convergence
-
Network Overlay and Hub Support (optional):
- Groups geographically-close data centers
- Designates hub data centers for inter-group communication
- Further reduces communication overhead in larger deployments
These components work together to dramatically reduce communication over WANs while ensuring algorithm convergence, enabling efficient geo-distributed machine learning.
What is an Approximate Synchronous Parallel model?
The Approximate Synchronous Parallel (ASP) model is a novel synchronization approach introduced by Gaia for communication between parameter servers across data centers. Its key characteristics include:
-
Focus on Approximation Rather Than Staleness:
- Unlike SSP (Stale Synchronous Parallel) which bounds how stale (old) a parameter can be
- ASP bounds how inaccurate a parameter can be compared to the most up-to-date value
-
Significance-Based Communication:
- Only communicates updates that cause significant changes to parameter values
- Based on empirical finding that 95-99% of updates cause less than 1% change to parameter values
- Allows insignificant updates to be aggregated until they become significant enough
-
Flexible Communication Timing:
- Delays synchronization indefinitely as long as the aggregated update remains insignificant
- Provides high flexibility in performing updates compared to time-based approaches
-
Dynamic Significance Threshold:
- Initially uses a user-defined significance threshold (typically 1-2%)
- Automatically reduces threshold over time (1/√t where t is the iteration number)
- Ensures convergence to optimal parameter values
-
Selective Barriers and Clock Monitoring:
- Uses selective barriers to ensure significant updates are recognized across data centers
- Mirror clock mechanism ensures bounded divergence between data centers
- Prevents any data center from getting too far ahead of others
-
Theoretical Guarantees:
- Provides mathematical proof of convergence for stochastic gradient descent
- Ensures machine learning algorithms will converge despite approximations
ASP essentially treats machine learning as an approximate computing problem, recognizing that not all updates need to be communicated immediately to achieve good results, which makes it well-suited for geo-distributed settings with limited WAN bandwidth.
What are the performance benefits of this model – specifically be able to explain why, what is being eliminated in terms of costs, overheads… in order to get to the specific performance gain.
The performance benefits of Gaia's Approximate Synchronous Parallel (ASP) model come from eliminating several key costs and overheads:
Eliminated Communication Overhead:
-
Insignificant Update Filtering:
- Eliminates 95-99% of updates that cause less than 1% change to parameter values
- Reduces WAN traffic by orders of magnitude while preserving model accuracy
-
Reduced Parameter Transfer:
- Only transfers parameters with significant aggregated changes
- Transfers these parameters only when necessary, not on a fixed schedule
Specific Performance Gains:
-
Execution Speed Improvements:
- 1.8-53.5× speedup over state-of-the-art parameter server systems
- Performance within 0.94-1.40× of running on a LAN (in a single data center)
- For Matrix Factorization: 25.4× speedup in low-bandwidth settings
- For Topic Modeling: 14.1× speedup in low-bandwidth settings
- For Image Classification: 53.5× speedup in low-bandwidth settings
-
Cost Reduction:
- 2.6-59.0× reduction in monetary cost compared to baseline approaches
- Eliminates both data transfer costs and machine time spent waiting for networks
- Especially significant in low-bandwidth WAN settings
-
Bandwidth Utilization Improvement:
- Makes efficient use of available WAN bandwidth for only significant updates
- Dynamically adapts to available bandwidth between different data centers
- Fully utilizes abundant LAN bandwidth within each data center
-
Resource Efficiency:
- Workers in each data center need to synchronize only with local parameter servers
- Less waiting time for parameter updates from distant data centers
- Iterations can complete faster within each data center
The key insight enabling these gains is the empirical observation that the vast majority of updates in machine learning algorithms cause only tiny changes to parameter values. By eliminating the communication of these insignificant updates over expensive, limited WANs while ensuring all significant updates are synchronized in a timely manner, Gaia achieves near-LAN performance in geo-distributed settings without compromising algorithm convergence.
Can you explain the different configurations of the experiments evaluated to generate the data in the results shown in the Lesson?
The lecture describes several experimental configurations used to evaluate distributed machine learning systems:
Deployment Settings:
-
LAN - Deployment within a single data center, representing the ideal case where all communication is on a local area network.
-
EC2-ALL - Deployment across 11 EC2 regions (Virginia, California, Oregon, Ireland, Frankfurt, Tokyo, Seoul, Singapore, Sydney, Mumbai, and São Paulo), representing a globally distributed setting.
-
V/C WAN - Deployment across two data centers with WAN bandwidth matching Virginia and California, representing a distributed ML setting within a continent.
-
S/S WAN - Deployment across two data centers with WAN bandwidth matching Singapore and São Paulo, representing the lowest WAN bandwidth between any two Amazon EC2 regions.
Systems Evaluated:
-
Baseline - State-of-the-art parameter server systems (IterStore for CPU-based and GeePS for GPU-based workloads) deployed across multiple data centers. Workers handle data in their data center while parameter servers are distributed across all data centers.
-
Gaia - The proposed system that decouples synchronization within a data center from synchronization between data centers, using the ASP model.
-
LAN - Baseline parameter servers deployed within a single data center that already holds all data, representing the performance upper bound.
Synchronization Models:
-
BSP (Bulk Synchronous Parallel) - Synchronizes all updates after each worker completes its iteration; workers must see the most up-to-date model before proceeding.
-
SSP (Stale Synchronous Parallel) - Allows the fastest worker to be ahead of the slowest by a bounded number of iterations; workers may proceed with bounded stale models.
Machine Learning Applications:
-
Matrix Factorization (MF) - A technique for recommender systems using the Netflix dataset.
-
Topic Modeling (TM) - An unsupervised method for discovering hidden semantic structures in documents using the Nytimes dataset.
-
Image Classification (IC) - A deep learning task using convolutional neural networks (GoogLeNet) on the ImageNet dataset.
Performance Metrics:
-
Execution time until convergence - Time taken to reach a specified objective function value.
-
Cost of algorithm convergence - Monetary cost based on Amazon EC2 pricing, including server time and data transfer costs.
The results showed significant performance degradation (3.5-23.8× slower) when naively running parameter server systems on WANs compared to LANs. Gaia dramatically improved performance, approaching LAN speeds even in geo-distributed settings, while significantly reducing costs.
What are some advantages of a decentralized peer-to-peer model over a federated or a centralized approach?
According to the lecture, a decentralized peer-to-peer model like Cartel offers several advantages over federated or centralized approaches:
Advantages over Centralized Approach:
-
Reduced Data Transfer:
- Eliminates the need to move raw data to a central location
- Reduces data transfer requirements by several orders of magnitude (~1500×)
- Avoids overwhelming network bandwidth with large data transfers
-
Data Sovereignty Compliance:
- Raw data remains in its original location
- Avoids cross-border data transfer issues and privacy concerns
-
Lower Training Time:
- Reduced training time by up to 5.7× compared to centralized approaches
- No waiting for data movement to central locations before training
Advantages over Federated Approach:
-
Smaller, Tailored Models:
- Creates smaller models (reduced by up to 3×) tailored to each node
- Leverages locality in the data trends specific to each location
- Avoids the "one size fits all" problem of global models
-
Reduced Overfitting:
- Global models can lead to overfitting and less accurate results
- Local models can be more precisely tuned to local data patterns
-
Dynamic Adaptation:
- Adapts 8× faster than isolated learning when new patterns emerge
- Can selectively transfer knowledge from peers when needed
- Combines benefits of isolation and collaboration
-
Efficient Resource Utilization:
- Lower computational requirements due to smaller models
- No need to maintain parameters for patterns not observed locally
- Better performance with the same computational resources
-
Selective Knowledge Sharing:
- Only transfers knowledge when necessary (upon drift detection)
- Shares only with relevant peers (logical neighbors)
- More bandwidth-efficient than broadcasting all updates to all nodes
A key insight from the lecture is that there's significant locality in data trends at different locations (e.g., patterns observed at cell towers). A peer-to-peer model like Cartel takes advantage of this locality while still enabling collaboration when needed, creating an efficient middle ground between fully isolated learning and globally centralized or federated approaches.
What are some of the challenges in realizing a peer-to-peer learning system such as Cartel?
According to the lecture, realizing a peer-to-peer learning system like Cartel presents several key challenges:
-
Determining When to Collaborate:
- Deciding when to execute collaborative model transfer between edge clouds
- Detecting when a model's accuracy has decreased significantly enough to warrant seeking help
- Creating mechanisms to quickly detect and react to variations in workload or edge stack configuration
-
Identifying Appropriate Peers (Logical Neighbors):
- Discovering which nodes have relevant knowledge for a specific problem
- Finding nodes with similar data distributions or configurations
- Dynamically finding appropriate peers as data patterns change over time
- Making nodes "oblivious" to data trends at other edges while still enabling collaboration
-
Knowledge Transfer Mechanisms:
- Determining how to effectively transfer knowledge between models
- Deciding whether to merge model portions or replace local models
- Creating transferable representations of knowledge between different nodes
- Balancing the trade-offs between model updating approaches
- Considering factors like feature sets, model update frequency, and network efficiency
-
Metadata Management:
- Creating efficient means to share metadata about models without revealing raw data
- Building systems to store, compare, and act on metadata at scale
- Determining what metadata is most useful for finding compatible peers
-
Drift Detection:
- Implementing reliable mechanisms to detect when a model is no longer performing well
- Distinguishing between temporary fluctuations and significant drift requiring intervention
- Balancing sensitivity of drift detection to avoid unnecessary collaboration
-
Coordination Infrastructure:
- Implementing a metadata service to aggregate information about models across nodes
- Ensuring the coordination system itself is efficient and scalable
- Managing communication between potentially thousands of edge nodes
-
Privacy and Data Protection:
- Ensuring knowledge transfer does not inadvertently reveal sensitive information
- Maintaining data locality and sovereignty while still enabling collaboration
-
System Integration:
- Creating APIs and abstractions that work across different machine learning algorithms
- Building interfaces for model-specific knowledge transfer operations
- Making the system generic enough to work with varied ML applications
Cartel addresses these challenges through mechanisms like a centralized metadata service, drift detection algorithms, logical neighbor identification based on data similarity, and knowledge transfer protocols that selectively share model components between peers.
Thoughts on Ray
Ray is a unified framework for distributed machine learning. Based on the limited information provided:
Ray is described as a system developed by the RISE lab at Berkeley that integrates all functionalities of the machine learning pipeline in a single unified framework. According to the lecture:
-
Ray integrates various components of the end-to-end machine learning pipeline including:
- Model creation and optimization
- Data delivery
- Execution of distributed tensor manipulations
- Model serving/inference
-
This integration "opens up many efficiencies in the end-to-end process" that would otherwise be lost when trying to coordinate different specialized systems.
-
The lecture refers to Ray's paper from OSDI 2018 and mentions Ian Stoica's keynote from Hot Storage 2020 for more information.
Ray is positioned as a comprehensive framework addressing the entire ML pipeline, which is a different focus from the geo-distributed training systems (Gaia, Federated Learning) and collaborative edge learning (Cartel).
Ray takes a more holistic view of the ML pipeline beyond just the distributed training aspect, which could potentially address integration challenges between different stages of ML workflows.