Developed by researchers at Cornell University, chain replication provides a way to coordinate clusters of servers to create large-scale storage services with high throughput, high availability, and strong consistency guarantees. This approach has advantages over several existing approaches that sacrifice consistency for scalability.
How Chain Replication Works
The core intuition behind chain replication is to arrange the servers storing replicas of an object into a chain. Client update requests go to the head of the chain, while query requests go to the tail. Updates propagate through the chain from head to tail.
This approach offers several advantages:
-
High throughput - By separating the roles of processing updates and queries, chain replication allows for efficient parallel processing.
-
Strong consistency - All queries are processed by the tail, which always has the latest updates, ensuring strong consistency.
-
High availability - If a server fails, it can be quickly removed from the chain with minimal disruption.
-
Scalability - The system can scale to handle large numbers of objects by using multiple independent chains.
Building a Chain
The process of organizing nodes into a chain for chain replication involves several steps:
-
Initial Setup:
- A set of servers is designated to store replicas of a particular object or volume.
- These servers are arranged in a linear order, forming a chain.
- The first server in the chain is designated as the "head", and the last server is designated as the "tail".
-
Role Assignment:
- The head server is responsible for receiving and processing all update requests from clients.
- The tail server handles all query requests from clients.
- Intermediate servers in the chain forward updates and acknowledge their completion.
-
Chain Maintenance:
- A separate component called the "master" monitors the health of all servers in the chain.
- The master is responsible for detecting server failures and reconfiguring the chain when necessary.
-
Failure Handling:
- If the head fails: The master removes it from the chain and promotes its successor to be the new head.
- If the tail fails: The master removes it and promotes its predecessor to be the new tail.
- If a middle server fails: The master removes it and connects its predecessor directly to its successor.
-
Adding New Servers:
- To maintain chain length or improve fault tolerance, new servers can be added to the chain.
- Typically, a new server is added at the end of the chain, becoming the new tail.
- The current tail forwards its stored data to the new server before it takes on the tail role.
-
Update Propagation:
- When the head receives an update, it processes it and then forwards the changes to its successor.
- Each server in the chain forwards the update to its successor after processing.
- The update is considered complete when it reaches and is processed by the tail.
-
Query Handling:
- All query requests are sent directly to the tail.
- The tail processes queries using its local copy of the data, which is guaranteed to reflect all completed updates.
-
Configuration Updates:
- The master informs all servers in the chain about any changes to the chain configuration.
- The master also notifies clients about changes to the head (for updates) or tail (for queries) when they occur.
This organization ensures that updates are processed in a consistent order while allowing queries to be handled efficiently by a single server (the tail) that always has the most up-to-date data. The chain structure also facilitates quick reconfiguration in response to server failures, helping to maintain high availability.
Handling failures
Chain replication handles failures in a robust and efficient manner, designed to minimize disruption and maintain strong consistency.
-
Failure Detection:
- The master component continuously monitors the health of all servers in the chain.
- If a server fails to respond or shows signs of malfunction, it is considered failed.
- The article mentions a conservative assumption of 10 seconds for failure detection.
-
Types of Failures:
-
Head Failure
- The master removes the failed head from the chain.
- The next server in line becomes the new head.
- Clients are notified to send future update requests to the new head.
- Query processing continues uninterrupted at the tail.
- There is a brief outage (about 2 message delays) for update processing while reconfiguration occurs.
-
Tail Failure
- The master removes the failed tail from the chain.
- The previous server in the chain becomes the new tail.
- Clients are notified to send future query requests to the new tail.
- Both query and update processing are unavailable for about 2 message delays during reconfiguration.
-
Middle Server Failure
- The master removes the failed server from the chain.
- The predecessor of the failed server connects directly to the successor.
- Query processing continues uninterrupted.
- Update processing may experience a delay but requests are not lost.
-
-
Recovery Process:
- After removing a failed server, the master selects a new server to add to the chain.
- Data recovery is initiated to bring the new server up to date.
- Recovery time is proportional to the amount of data stored and available network bandwidth.
-
Maintaining Consistency:
- When a server fails, its predecessor may have updates that haven't reached the rest of the chain.
- To maintain consistency, the predecessor forwards any pending updates to its new successor before normal operation resumes.
-
Parallel Recovery:
- In systems with many chains, multiple data recoveries can happen in parallel.
- This parallel recovery significantly reduces the window of vulnerability where additional failures could cause data loss.
-
Impact on Performance:
- During recovery, overall system throughput may decrease slightly due to fewer available servers and resources being used for data recovery.
- Once recovery is complete, performance typically returns to normal, though there may be some imbalance in load distribution.
-
Scalability of Failure Handling:
- The article discusses how different replica placement strategies (ring, random parallel, random sequential) affect the system's ability to handle failures as it scales to more servers.
- Random placement with parallel recovery was found to provide the best scalability in terms of maintaining availability as the system grows.
This failure handling approach allows chain replication to provide high availability and maintain strong consistency guarantees during server failures. The quick reconfiguration and targeted recovery process minimize the impact of failures on the overall system performance and reliability.
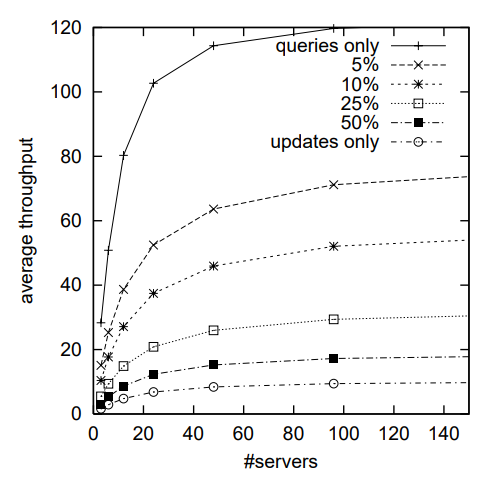
Performance Results
Simulations showed that chain replication outperforms traditional primary/backup approaches in most scenarios. It provides particularly good performance for workloads with a mix of updates and queries.
The researchers also found that random placement of data across servers, combined with parallel recovery after failures, allows chain replication to maintain high availability even as systems scale to thousands of servers.
Implications
Chain replication represents an important advance in distributed storage system design. By providing strong consistency without sacrificing performance or scalability, it opens up new possibilities for building large-scale online services and data-intensive applications.
While the current implementation is focused on local area networks, the researchers suggest the approach could potentially be extended to wide-area and heterogeneous environments in the future.
For developers and system architects working on scalable storage systems, chain replication offers an alternative to eventual consistency models, potentially simplifying application design while still delivering high performance at scale.
As online services continue to grow in size and complexity, techniques like chain replication will be crucial for building the robust, consistent, and scalable infrastructure needed to support them.
Key Concepts
Chain Replication: A technique for coordinating clusters of servers to create large-scale storage services with high throughput, high availability, and strong consistency guarantees.
Strong Consistency: A guarantee that all clients see the same data at the same time, regardless of which replica they access.
Scalability: The ability of a system to handle growing amounts of work or its potential to be enlarged to accommodate that growth.
Throughput: The amount of data or operations processed by a system in a given time period.
Availability: The proportion of time a system is in a functioning condition and accessible when required for use.
Fail-stop: An assumption that servers will halt in response to a failure rather than making erroneous state transitions, and that this halted state can be detected.
Head: In chain replication, the first server in the chain that receives and processes update requests from clients.
Tail: In chain replication, the last server in the chain that processes query requests from clients and sends replies.
Query: An operation that retrieves data from the storage system without modifying it.
Update: An operation that modifies data in the storage system.
Primary/Backup Approach: A traditional replication strategy where one server (the primary) handles all client requests and distributes updates to backup servers.
Eventual Consistency: A consistency model that guarantees that if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value.
Transient Outage: A temporary period during which a service is unavailable, often due to system reconfiguration after a failure.
Data Recovery: The process of restoring data to a replica after a failure or when adding a new replica to the system.
Replica Placement: The strategy used to decide which servers in a distributed system should store copies of each data item.
DHT (Distributed Hash Table): A decentralized distributed system that provides a lookup service similar to a hash table.
MTBU (Mean Time Between Unavailability): A metric used to measure the average time between incidents where data becomes unavailable in a storage system.
ROWAA (Read One, Write All Available): An approach to replication where read operations access a single replica, but write operations must be applied to all available replicas.
BibTex Citation
@inproceedings{van2004chain,
title={Chain Replication for Supporting High Throughput and Availability.},
author={Van Renesse, Robbert and Schneider, Fred B},
booktitle={OSDI},
volume={4},
number={91--104},
year={2004}
}