Unlike most data center storage architectures, Flat Data Center Storage (FDS) leverages full bisection bandwidth (bisection bandwidth is a measure of network performance that shows the bandwidth between two equal-sized parts of a network) networks and implementing clever data distribution and location schemes. FDS achieves high performance while simplifying application development. As networks continue to improve, more systems may adopt similar "flat" architectures, potentially reshaping the landscape of big data processing and storage.
For applications using big data and large-scale computing, efficient storage systems are crucial. FDS is a high-performance blob storage system that challenges traditional approaches to data center storage architecture.
The Problem with Traditional Data Center Storage
Historically, data centers have been built with oversubscribed networks, meaning that the bandwidth between racks was much lower than within racks. This led to a focus on data locality - keeping data close to the CPUs that process it. While this approach worked, it introduced several challenges:
- Complex programming models (e.g., MapReduce, Hadoop) to exploit data locality
- Inefficient resource utilization due to the fixed CPU-to-disk ratio on each node
- Difficulty in quickly reassigning tasks to different nodes
- Vulnerability to "straggler" nodes that slow down entire jobs
FDS: A New Approach
FDS differs from prior art in that it is built on the assumption that data center bandwidth is abundant. This is made possible by recent developments in full bisection bandwidth networks using Clos topologies (a type of network architecture used in large-scale data centers that is known for its reliability and ability to scale). With this foundation, FDS implements several key innovations:
- Flat Storage Model FDS returns to a conceptually simple, flat storage model where all compute nodes can access all storage with equal throughput. There are no "local" disks - all storage is treated as remote.
- Data Striping Data is divided into fixed-size units called "tracts" (typically 8MB) and distributed uniformly across all disks in the cluster. This approach provides natural load balancing and allows FDS to multiplex I/O across all available disks.
- Tract Locator Table (TLT) Instead of using a traditional metadata server to track data locations, FDS uses a clever hashing scheme. The Tract Locator Table (TLT) is a simple list of tractservers (disk servers) that clients use to deterministically locate data. This approach significantly reduces the load on the metadata server and allows for very fine-grained data access.
- Non-blocking API FDS provides a non-blocking API that allows applications to issue many parallel requests, fully utilizing the available network and disk bandwidth.
- Dynamic Work Allocation Because storage is treated uniformly, FDS can dynamically allocate work to compute nodes at a very fine granularity. This helps mitigate the "straggler" problem that plagues many distributed systems.
- Fast Failure Recovery FDS's design allows for extremely fast recovery from disk or machine failures. By leveraging the full bisection bandwidth network, all remaining disks can participate in rebuilding lost data in parallel.
Benefits of FDS
The FDS approach offers several significant benefits:
- Simplicity: Applications no longer need to worry about data locality, simplifying development.
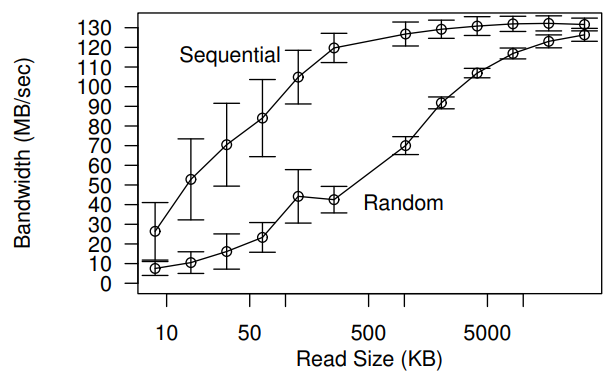
- Performance: FDS achieves high I/O performance, with single-process read and write speeds exceeding 2GB/s.
- Flexibility: Compute resources can be easily reassigned without moving data.
- Fault Tolerance: Fast recovery from failures improves overall system reliability.
- Scalability: The design scales well to very large clusters.
Key Concepts
Flat Data Center Storage (FDS): A high-performance, fault-tolerant, large-scale blob storage system that treats all storage as remote and accessible with equal throughput from any compute node.
Blob: In the context of FDS, a blob (Binary Large Object) is a collection of binary data stored as a single entity in the storage system. Blobs can be of any size up to the system's storage capacity.
Tract: The basic unit of data in FDS. A tract is a fixed-size portion of a blob, typically 8MB in size. Blobs are divided into tracts for storage and retrieval.
Tractserver: A process that manages a single disk in the FDS system, servicing read and write requests for tracts stored on that disk.
Full Bisection Bandwidth Network: A network architecture where any subset of nodes can communicate with any other subset at the full bandwidth of the nodes' network interface cards. This is typically achieved using CLOS network topologies.
CLOS Network: A multistage switching network that provides non-blocking connectivity between input and output ports. It is used in datacenters to achieve full bisection bandwidth.
Data Locality: The principle of keeping data close to the CPUs that process it. Traditional systems rely heavily on data locality for performance, while FDS makes it unnecessary.
Oversubscribed Network: A network where the aggregate bandwidth between nodes in different parts of the network (e.g., different racks) is less than the sum of the bandwidths of individual nodes. FDS is designed to work with non-oversubscribed networks.
Tract Locator Table (TLT): A data structure in FDS that maps tracts to tractservers. It is used by clients to deterministically locate data without querying a central metadata server for every operation.
Metadata Server: In FDS, a lightweight server that maintains the list of active tractservers and distributes the Tract Locator Table to clients. Unlike traditional systems, it is not involved in every read or write operation.
Data Striping: The technique of spreading data across multiple storage devices. In FDS, data is striped across all available disks in the form of tracts.
Non-blocking API: An API that allows operations to be initiated without waiting for previous operations to complete. FDS uses a non-blocking API to allow clients to issue many parallel requests.
Dynamic Work Allocation: The ability to assign computational tasks to nodes at runtime based on current system conditions. FDS's design allows for very fine-grained dynamic work allocation.
Straggler: In distributed computing, a task that takes an unusually long time to complete, thereby delaying the entire job. FDS's design helps mitigate the impact of stragglers.
Failure Recovery: The process of restoring lost data and maintaining system functionality after a component failure. FDS achieves very fast failure recovery by parallelizing the recovery process across all remaining disks.
Replication: The practice of storing multiple copies of data to improve durability and availability. FDS supports flexible replication schemes, including per-blob variable replication.
Blob Metadata: Information about a blob, such as its length, stored in a special "metadata tract" in FDS.
CreateBlob, ExtendBlobSize, DeleteBlob: Atomic operations in FDS for managing blobs. These operations are serialized to maintain consistency.
Heartbeat Messages: Regular messages sent from tractservers to the metadata server to indicate that they are still alive and functioning.
Table Versioning: A mechanism in FDS to ensure that clients are using up-to-date information about the location of data, especially after failures and recoveries.
BibTex Citation
@article{elson2013flat,
title={Flat Data Center Storage},
author={Elson, Jeremy and Nightingale, Edmund B},
journal={login Usenix Mag.},
volume={38},
number={1},
year={2013}
}