The core intuition of Raft is to simplify the consensus algorithm by making it more understandable and easier to implement than other consensus algorithms like Paxos. Raft operates under these key principles:
Strong Leadership
Raft uses a strong leader approach where the leader is responsible for managing the replicated log, handling client requests, and coordinating with followers. This centralization simplifies the system by ensuring that log entries only flow from the leader to the followers, reducing the complexity of maintaining consistency.
Decomposition of the Consensus Problem
Raft breaks down the consensus problem into three relatively independent subproblems:
- Leader Election: Ensuring that a new leader is elected when the current leader fails.
- Log Replication: The leader accepts log entries from clients and replicates them across the cluster.
- Safety: Ensuring that the system maintains consistency and correctness even in the presence of failures.
Randomized Leader Election
Raft uses randomized election timeouts to elect leaders. This reduces the likelihood of split votes and ensures that elections are resolved quickly and simply. Each server waits for a random period before starting an election, which helps in staggering the election attempts and reducing conflicts.
Log Matching Property
Raft ensures that logs are consistent across servers by maintaining the Log Matching Property:
- If two logs contain an entry with the same index and term, then the logs are identical in all preceding entries.
- This property is maintained through a consistency check during the AppendEntries RPC, where the leader ensures that followers' logs match its own before appending new entries.
Commitment and Safety
Raft guarantees that once a log entry is committed, it will not be lost. The leader only considers an entry committed once it has been replicated on a majority of the servers. This ensures that the system can tolerate failures and still maintain consistency.
Cluster Membership Changes
Raft handles changes in cluster membership through a joint consensus approach, where the system transitions through a configuration that includes both the old and new configurations. This ensures that there is no point during the transition where the system can split into two independent majorities, maintaining safety.
Snapshotting for Log Compaction
To prevent the log from growing indefinitely, Raft uses snapshotting to compact the log. Each server takes snapshots independently, covering just the committed entries in its log. This reduces the storage requirements and speeds up recovery times.
Client Interaction and Linearizability
Raft ensures linearizable semantics by having clients interact with the leader and by tracking the latest serial number processed for each client. This prevents duplicate execution of commands and ensures that read-only operations return the most up-to-date data.
By focusing on these principles, Raft achieves a balance between simplicity and robustness, making it easier to understand, implement, and maintain compared to other consensus algorithms.
Leader Election
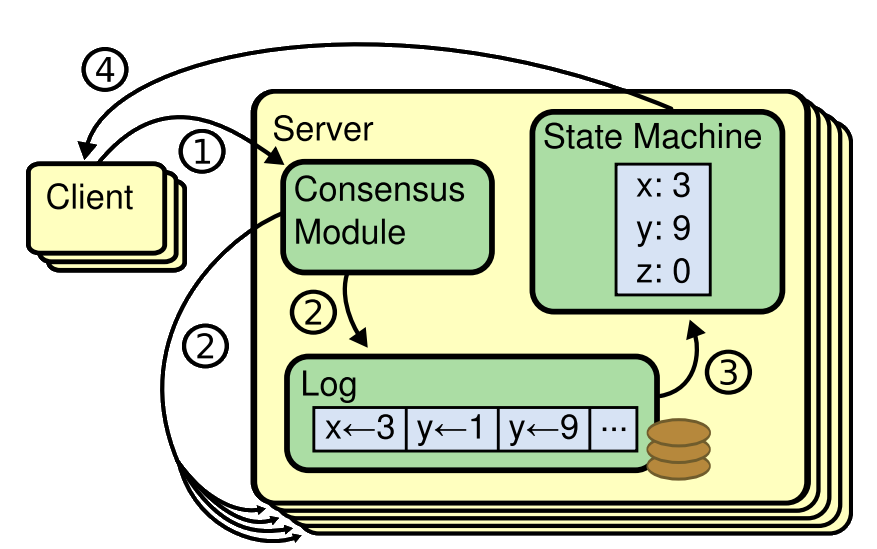
Leader election is a critical component in distributed systems to ensure that there is a single source of truth for log replication. Raft uses randomized timers to elect a leader, which helps in resolving conflicts quickly and simply. When a server starts up, it begins as a follower and remains in this state as long as it receives valid RPCs from a leader or candidate. If a follower receives no communication over a period of time called the election timeout, it assumes there is no viable leader and begins an election to choose a new leader. This process involves incrementing its term, voting for itself, and sending RequestVote RPCs to other servers. The candidate that receives votes from a majority of the servers becomes the leader.
Log Replication
Once a leader is elected, it begins servicing client requests. Each client request contains a command to be executed by the replicated state machines. The leader appends the command to its log as a new entry and issues AppendEntries RPCs in parallel to each of the other servers to replicate the entry. The leader decides when it is safe to apply a log entry to the state machines, and such an entry is called committed. Raft guarantees that committed entries are durable and will eventually be executed by all of the available state machines. A log entry is committed once the leader that created the entry has replicated it on a majority of the servers.
Safety and Consistency
Raft ensures safety by maintaining the following properties:
- Election Safety: At most one leader can be elected in a given term.
- Leader Append-Only: A leader never overwrites or deletes entries in its log; it only appends new entries.
- Log Matching: If two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
- Leader Completeness: If a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
- State Machine Safety: If a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
Handling Failures
Raft is designed to handle server failures gracefully. If a follower or candidate crashes, future RequestVote and AppendEntries RPCs sent to it will fail. Raft handles these failures by retrying indefinitely; if the crashed server restarts, the RPC will complete successfully. If a server crashes after completing an RPC but before responding, it will receive the same RPC again after it restarts. Raft RPCs are idempotent, so this causes no harm.
Timing and Availability
Raft's availability depends on the timing of events. The system must satisfy the following timing requirement: broadcastTime ≪ electionTimeout ≪ MTBF (Mean Time Between Failures). The broadcast time should be an order of magnitude less than the election timeout so that leaders can reliably send heartbeat messages to prevent followers from starting elections. The election timeout should be a few orders of magnitude less than MTBF to ensure steady progress.
Cluster Membership Changes
Raft supports dynamic changes to the cluster membership. This is crucial for maintaining system availability and reliability as servers are added or removed. Raft uses a two-phase approach to ensure safety during configuration changes. The cluster first switches to a transitional configuration called joint consensus, which combines both the old and new configurations. Once the joint consensus has been committed, the system transitions to the new configuration. This approach ensures that there is no point during the transition where it is possible for two leaders to be elected for the same term.
Log Compaction
To prevent the log from growing indefinitely, Raft uses snapshotting for log compaction. Each server takes snapshots independently, covering just the committed entries in its log. The snapshot includes the current state of the system and metadata such as the last included index and term. Once a server completes writing a snapshot, it may delete all log entries up to the last included index. If a follower lags significantly behind, the leader can send it a snapshot to bring it up to date.
Client Interaction
Clients interact with Raft by sending requests to the leader. If a client contacts a follower, the follower redirects it to the leader. To ensure linearizable semantics, clients assign unique serial numbers to every command. The state machine tracks the latest serial number processed for each client and the associated response. If a command with an already processed serial number is received, the state machine responds immediately without re-executing the request. For read-only operations, the leader must have the latest information on committed entries and must check if it has been deposed before processing the request.
Performance
Raft's performance is comparable to other consensus algorithms like Paxos. It achieves minimal message overhead by requiring only a single round-trip from the leader to a majority of the cluster for log replication. Raft supports batching and pipelining requests to improve throughput and reduce latency. Performance optimizations from other algorithms can also be applied to Raft.
Correctness
Raft's correctness is ensured through formal specifications and proofs. The algorithm has been formally specified using the TLA+ specification language, and its safety properties have been mechanically proven. This rigorous approach to correctness ensures that Raft can be reliably implemented and used in practical systems.
This detailed exploration of Raft highlights its design choices and mechanisms that make it a robust and understandable consensus algorithm for distributed systems. By focusing on understandability, Raft provides a solid foundation for building reliable and maintainable distributed systems.
Key Terms
AppendEntries RPC: A Remote Procedure Call used by the leader to replicate log entries across followers and to provide a form of heartbeat to maintain authority.
Broadcast Time: The average time it takes for a server to send RPCs in parallel to every server in the cluster and receive their responses.
Candidate: A server state in Raft during which a server attempts to become the leader by requesting votes from other servers.
Cluster Configuration: The set of servers participating in the consensus algorithm. Raft supports dynamic changes to this configuration.
Commit Index: The index of the highest log entry known to be committed, which means it is safe to apply to the state machine.
Consensus Algorithm: An algorithm used to achieve agreement on a single data value among distributed processes or systems. Raft and Paxos are examples of consensus algorithms.
Election Timeout: The period a follower waits without hearing from a leader before starting an election to become the new leader.
Follower: A passive server state in Raft that responds to requests from leaders and candidates but does not initiate actions on its own.
Heartbeat: A periodic signal sent by the leader to all followers to maintain its authority and prevent new elections.
Joint Consensus: A transitional configuration in Raft that combines both the old and new configurations during a cluster membership change to ensure safety.
Leader: The server in Raft that manages the replicated log, handles client requests, and coordinates with followers.
Leader Completeness Property: A property ensuring that if a log entry is committed in a given term, it will be present in the logs of the leaders for all higher-numbered terms.
Leader Election: The process of selecting a new leader when the current leader fails or steps down.
Leader Append-Only Property: A property ensuring that a leader never overwrites or deletes entries in its log; it only appends new entries.
Linearizability: A correctness condition for concurrent objects where each operation appears to execute instantaneously at some point between its invocation and its response.
Log Compaction: The process of reducing the size of the log by discarding obsolete information, typically through snapshotting.
Log Matching Property: A property ensuring that if two logs contain an entry with the same index and term, then the logs are identical in all preceding entries.
Majority: More than half of the servers in the cluster. Raft requires a majority to agree on decisions to ensure safety and progress.
MTBF (Mean Time Between Failures): The average time between failures for a single server, used to determine appropriate election timeouts.
Persistent State: State that is stored on stable storage and survives server restarts, such as the current term and the log.
Randomized Election Timeout: A technique used in Raft to prevent split votes by choosing election timeouts randomly from a fixed interval.
Replicated Log: A log that is maintained consistently across multiple servers in a distributed system, ensuring that all servers process the same sequence of commands.
Replicated State Machine: A state machine that is replicated across multiple servers, ensuring that each server computes identical copies of the same state.
RequestVote RPC: A Remote Procedure Call used by candidates to gather votes from other servers during leader election.
RPC (Remote Procedure Call): A protocol that one program can use to request a service from a program located on another computer in a network.
Safety: The property of a consensus algorithm that ensures it never returns an incorrect result under all non-Byzantine conditions.
Snapshotting: The process of taking a snapshot of the current state of the system and discarding the log entries up to that point to reduce log size.
State Machine Safety Property: A property ensuring that if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
Term: A logical time unit in Raft, numbered with consecutive integers, during which a leader is elected and serves until the end of the term.
Volatile State: State that is stored in memory and does not survive server restarts, such as the commit index and the last applied index.
@inproceedings{ongaro2014search,
title={In search of an understandable consensus algorithm},
author={Ongaro, Diego and Ousterhout, John},
booktitle={2014 USENIX annual technical conference (USENIX ATC 14)},
pages={305--319},
year={2014}
}