The core intuition of checkpoint-based rollback recovery is to periodically save the state of a distributed system so that, in the event of a failure, the system can be restored to a previously saved state, minimizing the loss of computation and ensuring consistency across all processes. Here are the key concepts:
-
Periodic State Saving: Processes in a distributed system periodically save their state to stable storage. These saved states are called checkpoints.
-
Consistency: The checkpoints must form a consistent global state, meaning that the saved states of all processes and the communication channels reflect a possible state of the system during failure-free execution.
-
Recovery Line: Upon a failure, the system rolls back to the most recent set of consistent checkpoints, known as the recovery line. This ensures that the system can restart from a known good state.
-
Minimizing Rollback: By saving states periodically, the amount of computation lost due to a rollback is minimized. The system only needs to redo the work done since the last checkpoint.
-
Coordination: Checkpoints can be taken in a coordinated manner (all processes synchronize to take checkpoints simultaneously) or uncoordinated manner (each process takes checkpoints independently). Coordinated checkpointing avoids the domino effect, where a failure in one process causes cascading rollbacks in others.
-
Garbage Collection: Old checkpoints that are no longer needed for recovery are discarded to free up storage space. This process is known as garbage collection.
-
Output Commit: Special care is taken to ensure that outputs to the outside world are consistent with the system's state. This often requires coordination to ensure that the state from which the output was generated is recoverable.
By implementing these principles, checkpoint-based rollback recovery provides a robust mechanism for fault tolerance in distributed systems, ensuring that the system can recover from failures with minimal disruption and data loss.
Uncoordinated Checkpointing
Uncoordinated checkpointing allows processes to independently decide when to take checkpoints, maximizing autonomy. However, this approach has several drawbacks:
- Domino Effect: Independent checkpoints can lead to cascading rollbacks, potentially losing significant computation work.
- Useless Checkpoints: Some checkpoints may never be part of a consistent global state, wasting resources.
- Garbage Collection: Multiple checkpoints need to be maintained and periodically cleaned up.
- Output Commit: Frequent output commits require global coordination, negating the autonomy advantage.
Coordinated Checkpointing
Coordinated checkpointing requires processes to synchronize their checkpoints to form a consistent global state. This method avoids the domino effect and simplifies recovery:
- Blocking Protocols: Simple but can result in high overhead due to communication blocking.
- Non-blocking Protocols: Use markers or checkpoint indices to avoid blocking, ensuring consistency without halting communication.
- Synchronized Clocks: Loosely synchronized clocks can trigger checkpoints simultaneously, reducing coordination overhead.
- Communication Reliability: Reliable channels may require saving in-transit messages as part of the checkpoint.
Communication-Induced Checkpointing (CIC)
CIC protocols prevent the domino effect without full coordination:
- Local and Forced Checkpoints: Processes take local checkpoints independently and forced checkpoints based on communication patterns.
- Z-paths and Z-cycles: These concepts help identify and prevent useless checkpoints by ensuring no Z-path becomes a Z-cycle.
- Model-Based Protocols: Use heuristics to detect and prevent patterns leading to useless checkpoints.
- Index-Based Protocols: Assign timestamps to checkpoints, ensuring consistency through forced checkpoints.
Log-Based Rollback Recovery
Pessimistic Logging
Pessimistic logging assumes failures can occur at any time, logging determinants synchronously to stable storage:
- Advantages: Simplifies recovery, garbage collection, and output commit. Protects surviving processes from rollback.
- Techniques: Special hardware, sender-based logging, and deferred logging reduce performance overhead.
Optimistic Logging
Optimistic logging logs determinants asynchronously, assuming failures are rare:
- Advantages: Lower failure-free performance overhead.
- Challenges: Complicated recovery, garbage collection, and output commit. Requires tracking causal dependencies to manage orphan processes.
Causal Logging
Causal logging combines the advantages of optimistic and pessimistic logging:
- Advantages: Low performance overhead, fast output commit, and no orphan processes.
- Techniques: Piggybacking determinants on messages and using antecedence graphs to track causality.
Implementation Issues
Checkpointing Implementation
- Concurrent Checkpointing: Uses memory protection to save state while the process continues execution.
- Incremental Checkpointing: Saves only modified state portions, reducing overhead.
- System-Level vs. User-Level: Kernel-level implementations are powerful but non-portable, while user-level implementations are more portable but less comprehensive.
- Compiler Support: Compilers can optimize checkpoint placement and state saving, though practical challenges exist.
Communication Protocols
- Location-Independent Identities: Mask process identities to allow recovery on different machines.
- Reliable Channel Protocols: Require additional support to handle in-transit messages and re-establish connections after failures.
Log-Based Recovery
- Message Logging Overhead: Techniques like sender-based logging and copy-on-write reduce overhead.
- Combining with Coordinated Checkpointing: Reduces stable storage access and simplifies implementation.
Stable Storage
- Magnetic Disks: Common but slow; direct disk access bypasses file system overhead.
- Non-Volatile Memory: Faster but limited by cost and capacity.
Support for Nondeterminism
- System Calls: Classified into idempotent, replay-only, and re-executable calls.
- Asynchronous Signals: Techniques like instruction counters track and replay signals accurately.
Recovery Handling
- Reinstating Processes: Insulate processes from environment-specific variables and recreate kernel data structures.
- Behavior During Recovery: Optimizations like sender and receiver logging balance performance during failure-free execution and recovery.
Checkpointing and Mobility
- Mobile Computing: Protocols must handle energy constraints, intermittent communication, and low-performance processors. Independent and communication-induced checkpointing are more suitable.
Key Terms
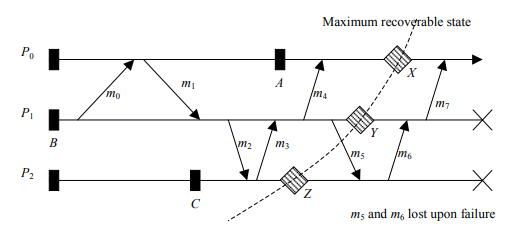
- Output Commit Problem: Ensuring that the state from which a message is sent to the outside world is recoverable despite future failures.
- Checkpoint Interval: The period between two consecutive checkpoints.
- Antecedence Graph: A graph representing the causal relationships between nondeterministic events, used in causal logging.
Checkpointing
- Checkpoint: A saved state of a process at a specific point in time, used to restore the process after a failure.
- Coordinated Checkpointing: A technique where all processes in a distributed system synchronize to take checkpoints simultaneously, ensuring a consistent global state.
- Uncoordinated Checkpointing: Each process independently decides when to take checkpoints, which can lead to the domino effect.
- Communication-Induced Checkpointing (CIC): A hybrid approach where processes take local checkpoints independently and forced checkpoints based on communication patterns to prevent the domino effect.
Logging
- Message Logging: Recording the messages sent and received by processes to enable recovery by replaying these messages.
- Pessimistic Logging: Logs determinants synchronously to stable storage, ensuring no orphan processes but with higher performance overhead.
- Optimistic Logging: Logs determinants asynchronously, assuming failures are rare, which reduces overhead but complicates recovery.
- Causal Logging: Combines the benefits of optimistic and pessimistic logging by ensuring determinants are either stable or available locally, preventing orphan processes.
Recovery
- Rollback Recovery: A technique to restore a system to a previous consistent state after a failure by rolling back to checkpoints and replaying logged messages.
- Domino Effect: A situation where a failure in one process causes a cascade of rollbacks in other processes, potentially losing significant computation work.
- Orphan Process: A process that depends on a nondeterministic event whose determinant cannot be recovered, leading to inconsistencies.
Consistency
- Global State: The collection of individual states of all processes and communication channels in a distributed system.
- Consistent Global State: A global state that could occur during a failure-free execution, where all message receipts are matched by corresponding sends.
- Z-path: A sequence of messages that connects two checkpoints, used to detect and prevent useless checkpoints.
- Z-cycle: A Z-path that starts and ends at the same checkpoint, indicating a potential for useless checkpoints.
System Models
- Piecewise Deterministic (PWD) Assumption: Assumes that all nondeterministic events can be identified and logged, allowing deterministic replay during recovery.
- Stable Storage: A storage medium that survives failures, used to save checkpoints and logs.
Protocols and Algorithms
- Garbage Collection: The process of reclaiming storage space used by checkpoints and logs that are no longer needed for recovery.
- Dependency Tracking: Monitoring the dependencies between processes to ensure consistent recovery and prevent orphan processes.
- Instruction Counter: A hardware or software mechanism to track the number of instructions executed, used to accurately replay asynchronous events.
@article{elnozahy2002survey,
title={A survey of rollback-recovery protocols in message-passing systems},
author={Elnozahy, Elmootazbellah Nabil and Alvisi, Lorenzo and Wang, Yi-Min and Johnson, David B},
journal={ACM Computing Surveys (CSUR)},
volume={34},
number={3},
pages={375--408},
year={2002},
publisher={ACM New York, NY, USA}
}