The core intuition behind Spanner is to create a globally-distributed database that combines the benefits of traditional relational databases with the scalability and fault tolerance of distributed systems. Here are the key concepts that drive Spanner's design:
-
Global Distribution with Consistency: Spanner aims to manage data across multiple datacenters worldwide while maintaining strong consistency. This is achieved through the use of the Paxos consensus algorithm for replication, ensuring that all replicas agree on the state of the data.
-
TrueTime API: A critical innovation in Spanner is the TrueTime API, which provides globally-synchronized timestamps with bounded uncertainty. This allows Spanner to assign globally-meaningful commit timestamps to transactions, ensuring external consistency (linearizability) across the entire system.
-
Automatic Sharding and Resharding: Spanner automatically shards data across many sets of Paxos state machines and dynamically reshards data as the amount of data or the number of servers changes. This ensures that the system can scale efficiently and balance load across datacenters.
-
Synchronous Replication: By using synchronous replication, Spanner ensures that data is consistently replicated across multiple locations. This provides high availability and durability, even in the face of datacenter failures.
-
Support for SQL and Transactions: Spanner provides a SQL-based query language and supports general-purpose transactions. This makes it easier for developers to use Spanner for a wide range of applications, from simple key-value stores to complex relational databases.
-
Data Locality and Placement: Spanner allows applications to control the geographic placement of their data, optimizing for latency and availability. This is done through a flexible replication configuration that can be dynamically adjusted based on application needs.
-
Scalability and Performance: Spanner is designed to scale up to millions of machines across hundreds of datacenters, handling trillions of database rows. The system's architecture and use of efficient concurrency control mechanisms ensure high performance and low latency.
Architecture and Implementation
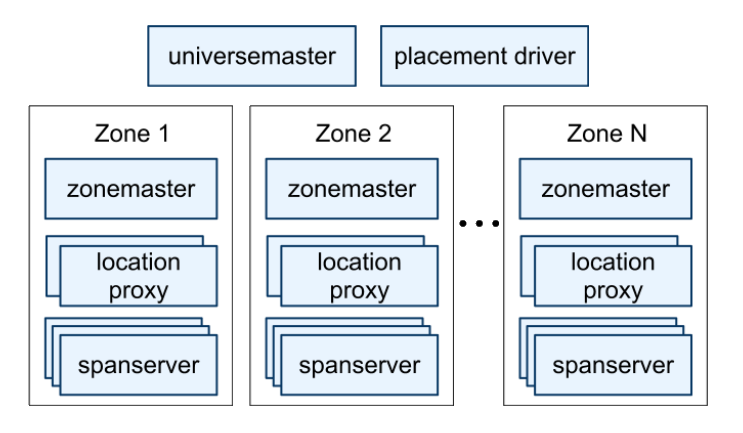
Spanner is a globally-distributed database designed to manage data across multiple datacenters, ensuring high availability and fault tolerance. The architecture is organized into zones, each containing a zonemaster and multiple spanservers. The zonemaster assigns data to spanservers, while spanservers handle data storage and client requests. The universe master and placement driver manage the overall system, ensuring data is balanced and replication constraints are met.
A key component of Spanner's architecture is the use of Paxos state machines for replication. Each spanserver implements a Paxos state machine for each tablet, ensuring data consistency across replicas. The system supports long-lived leaders with time-based leases, enhancing performance and reducing the overhead of leader elections.
Data Model and Transactions
Spanner's data model is based on schematized semi-relational tables, supporting a SQL-like query language. This model allows for complex queries and transactions, making it suitable for a wide range of applications. Data is versioned, with each version timestamped at commit time, enabling historical reads and consistent backups.
Transactions in Spanner are managed using two-phase commit, ensuring atomicity and consistency across multiple Paxos groups. The system supports both read-write and read-only transactions, with the latter benefiting from snapshot isolation. Spanner's concurrency control is based on two-phase locking, with additional mechanisms to handle long-lived transactions efficiently.
TrueTime and External Consistency
A novel feature of Spanner is the TrueTime API, which provides globally-synchronized timestamps with bounded uncertainty. TrueTime is implemented using a combination of GPS and atomic clocks, ensuring high accuracy and reliability. This API is crucial for maintaining external consistency, allowing Spanner to provide strong guarantees about the order of transactions.
TrueTime enables several advanced features, such as non-blocking reads in the past, lock-free read-only transactions, and atomic schema changes. By exposing clock uncertainty directly, TrueTime allows Spanner to manage distributed transactions with minimal latency and high precision.
Performance and Scalability
Spanner is designed to scale to millions of machines across hundreds of datacenters, handling trillions of database rows. The system automatically reshards data and migrates it across machines to balance load and respond to failures. This dynamic management ensures that Spanner can handle large-scale applications with varying workloads.
Performance benchmarks show that Spanner can achieve high throughput and low latency for both reads and writes. The system's use of long-lived Paxos leaders and efficient concurrency control mechanisms contribute to its performance. Additionally, Spanner's ability to dynamically adjust replication configurations and data placement helps maintain optimal performance under different conditions.
Use Cases and Applications
Spanner is used by various applications within Google, including the F1 advertising backend. F1 leverages Spanner's strong consistency and high availability to manage a large, complex dataset with minimal manual intervention. The system's support for synchronous replication and automatic failover ensures that F1 can handle outages and maintain service continuity.
Other applications benefit from Spanner's flexible data model and powerful query capabilities. The system's ability to handle complex, evolving schemas and provide consistent reads across datacenters makes it suitable for a wide range of use cases, from interactive services to large-scale data analysis.
Conclusion
Its architecture, data model, and use of TrueTime enable it to provide strong consistency, high availability, and excellent performance at a global scale.
Key Terms
-
Spanner: A globally-distributed database developed by Google, designed to manage data across multiple datacenters with high availability and fault tolerance.
-
Paxos: A consensus algorithm used to achieve agreement on a single value among distributed systems. In Spanner, Paxos is used for data replication to ensure consistency across replicas.
-
TrueTime: A Google API that provides globally-synchronized timestamps with bounded uncertainty, crucial for maintaining external consistency in distributed transactions.
-
External Consistency: Also known as linearizability, it ensures that the results of operations are consistent with a single, global order of execution.
-
Two-Phase Commit (2PC): A protocol used to ensure all participants in a distributed transaction agree on the transaction's outcome (commit or abort), ensuring atomicity.
-
Snapshot Isolation: A concurrency control mechanism that allows transactions to operate on a consistent snapshot of the database, providing isolation from other concurrent transactions.
-
Zonemaster: A component in Spanner that assigns data to spanservers within a zone and manages the overall data distribution and replication within that zone.
-
Spanserver: A server in Spanner responsible for storing data and handling client requests. Each spanserver manages multiple tablets and implements Paxos state machines.
-
Tablet: A data structure in Spanner similar to Bigtable's tablet, representing a bag of key-value mappings. Tablets are the basic unit of data storage and replication.
-
Directory: A set of contiguous keys that share a common prefix, used in Spanner to manage data locality and replication configurations.
-
Commit Wait: A mechanism in Spanner where the coordinator leader waits until the commit timestamp is guaranteed to be in the past, ensuring external consistency.
-
Lock Table: A data structure used to manage locks for two-phase locking in Spanner, ensuring concurrency control for transactional reads and writes.
-
Leader Lease: A time-based lease granted to a Paxos leader, allowing it to act as the leader for a specified duration. This helps manage leadership and ensure consistency.
-
Atomic Schema Changes: Changes to the database schema that are applied atomically, ensuring that all replicas see the schema change simultaneously.
-
Megastore: A storage system developed by Google that provides a semi-relational data model and synchronous replication, influencing the design of Spanner.
-
Bigtable: A distributed storage system developed by Google for managing structured data, serving as a foundation for Spanner's design.
-
Colossus: The successor to the Google File System (GFS), used by Spanner for distributed file storage.
-
Concurrency Control: Mechanisms used to manage simultaneous operations on a database to ensure consistency and isolation.
-
Replication: The process of copying data across multiple servers or datacenters to ensure availability and fault tolerance.
-
Shard: A subset of a database's data, distributed across multiple servers to balance load and improve performance.
-
Latency: The time taken for a data operation (such as a read or write) to complete in a distributed system.
-
Throughput: The number of operations a system can handle in a given period, indicating its performance capacity.
-
Failover: The process of automatically switching to a standby server or system component in case of failure, ensuring continuous availability.
-
Garbage Collection: The process of automatically deleting old or unnecessary data versions to free up storage space.
-
SQL: Structured Query Language, used for managing and querying relational databases. Spanner supports a SQL-based query language.
-
MapReduce: A programming model for processing large data sets with a distributed algorithm on a cluster, supported by Spanner for consistent executions.
-
Cluster Management: The process of managing a group of interconnected servers (a cluster) to ensure efficient operation and resource utilization.
-
Consistency: Ensuring that all replicas in a distributed system reflect the same data state, even in the presence of concurrent operations.
-
Availability: The ability of a system to remain operational and accessible, even in the face of failures or maintenance activities.
-
Durability: The property that ensures data remains intact and recoverable after a transaction has been committed, even in the event of a system crash.
@article{corbett2013spanner,
title={Spanner: Google's globally distributed database},
author={Corbett, James C and Dean, Jeffrey and Epstein, Michael and Fikes, Andrew and Frost, Christopher and Furman, Jeffrey John and Ghemawat, Sanjay and Gubarev, Andrey and Heiser, Christopher and Hochschild, Peter and others},
journal={ACM Transactions on Computer Systems (TOCS)},
volume={31},
number={3},
pages={1--22},
year={2013},
publisher={ACM New York, NY, USA}
}