In a recent talk, Google Senior Fellow Jeff Dean discussed the evolution of cloud computing systems over the past few decades and shared insights on the future of machine learning infrastructure.
Key Highlights:
-
The journey from early utility computing systems like Multics in the 1960s to today's massive data centers spanning multiple football fields.
-
Google's pioneering work in using commodity hardware at scale.
-
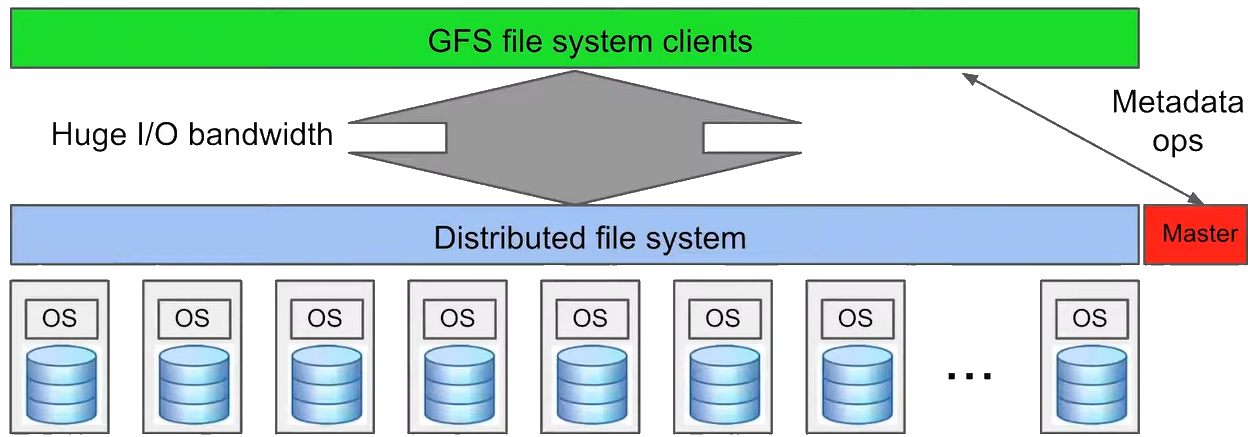
The development of critical distributed systems abstractions like the Google File System (GFS) and MapReduce, which enabled processing massive datasets across thousands of machines.
- The Google File System (GFS): A distributed file system designed to provide efficient, reliable access to data using large clusters of commodity hardware.
- MapReduce: A programming model and implementation for processing and generating large datasets across clusters of machines.
- Bigtable: A distributed storage system for managing structured data at massive scale.
-
Evolution of storage systems from BigTable to Spanner, providing structured data storage and manipulation at unprecedented scale.
-
The rise of container technologies and cluster management systems like Borg for efficiently utilizing data center resources.
-
How machine learning is transforming computing, driving the development of specialized hardware like Google's Tensor Processing Units (TPUs).
-
The progression of machine learning frameworks from Theano and Torch to TensorFlow and PyTorch.
There are several key design patterns that have proven successful across multiple systems:
- Using a centralized master for metadata and control while distributing actual work/data across thousands of machines
- Breaking work into many small units to enable dynamic load balancing and fast recovery from failures
- Providing higher-level abstractions to hide the complexity of distributed systems from application developers
Looking ahead, there is a great potential for more heterogeneous computing systems that combine specialized accelerators for different tasks. ML models can flexibly compose pre-trained components to tackle new problems without starting from scratch each time.
As these technologies continue to advance, they promise to unlock new possibilities in artificial intelligence, scientific computing, and beyond.
The technical roadmap for the future suggests this is still in the early stages of a computing revolution driven by machine learning and specialized hardware.
Key Concepts
Cloud Computing: A model for delivering computing services over the internet, including servers, storage, databases, networking, software, and analytics.
Multics (Multiplexed Information and Computing Service): An early time-sharing operating system developed in the 1960s that influenced many modern operating systems.
Commodity Hardware: Standard, off-the-shelf computer components, as opposed to specialized or high-end hardware.
Google File System (GFS): A distributed file system developed by Google for efficient, reliable access to data using large clusters of commodity hardware.
MapReduce: A programming model and implementation for processing and generating large datasets with a parallel, distributed algorithm on a cluster.
BigTable: A distributed storage system for managing structured data designed to scale to very large sizes across thousands of commodity servers.
Spanner: Google's globally distributed database that provides strong consistency and supports distributed transactions across multiple data centers.
Virtual Machines (VMs): Software emulations of computer systems that provide the functionality of a physical computer.
Containers: A lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings.
Borg: Google's cluster management system that runs hundreds of thousands of jobs across a number of clusters each with up to tens of thousands of machines.
Tensor Processing Unit (TPU): A custom-developed application-specific integrated circuit (ASIC) by Google specifically for neural network machine learning.
GPU (Graphics Processing Unit): A specialized processor originally designed to accelerate graphics rendering, now also used for computational tasks, particularly in machine learning.
Machine Learning (ML): A subset of artificial intelligence that involves algorithms and statistical models that computer systems use to perform a specific task without using explicit instructions, relying on patterns and inference instead.
Neural Network: A series of algorithms that endeavors to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates.
Theano: An open-source numerical computation library for Python, primarily used for machine learning research.
Torch: An open-source machine learning library, scientific computing framework, and script language based on Lua.
TensorFlow: An open-source software library for dataflow and differentiable programming across a range of tasks, developed by Google.
PyTorch: An open-source machine learning library based on the Torch library, used for applications such as computer vision and natural language processing.
JAX: A system for high-performance machine learning research developed by Google.
XLA (Accelerated Linear Algebra): A domain-specific compiler for linear algebra that optimizes TensorFlow computations.
MLIR (Multi-Level Intermediate Representation): A new compiler infrastructure that addresses software fragmentation, improves compilation for heterogeneous hardware, and significantly reduces the cost of building domain-specific compilers.
Edge Computing: A distributed computing paradigm that brings computation and data storage closer to the sources of data.
Fault Tolerance: The property that enables a system to continue operating properly in the event of the failure of some of its components.
Load Balancing: The process of distributing network or application traffic across multiple servers to ensure no single server bears too much demand.
Latency: The time delay between the cause and the effect of some physical change in the system being observed.