Scaling Memcache at Facebook: Lessons from a Billion Operations per Second
In the world of large-scale web applications, performance and scalability are paramount. Facebook, with its massive user base and real-time communication requirements, faces unique challenges in this arena. In a recent talk, Rajesh Nishtala, an engineer at Facebook, shared insights into how the company scaled its memcache infrastructure to handle over a billion operations per second.
Facebook's scaling of memcache offers valuable insights for any organization dealing with large-scale distributed systems. By continuously innovating and addressing challenges at each scale, Facebook has built a caching system capable of handling over a billion operations per second.
The lessons learned emphasize the importance of client-side optimizations, the balance between performance and operational efficiency, and the benefits of separating caching from persistent storage. As web applications continue to grow in scale and complexity, these insights will undoubtedly prove valuable for engineers and architects alike.
The Challenge
Facebook's infrastructure requirements:
- Near real-time communication
- On-the-fly content aggregation from multiple sources
- Sharing and updating highly popular content
- Processing millions of user requests per second
These requirements translate into a need for:
- Supporting over a billion gets per second
- Storing trillions of items in cache
- Geographical distribution
- Supporting a constantly evolving product
- Rapid deployment of new features
The Evolution of Facebook's Caching System
From Databases to Memcache
Initially, Facebook relied solely on databases. However, as the complexity of data dependencies grew, even for small user requests, it became clear that databases alone could not handle the load. This led to the introduction of memcache servers.
Single Cluster Implementation
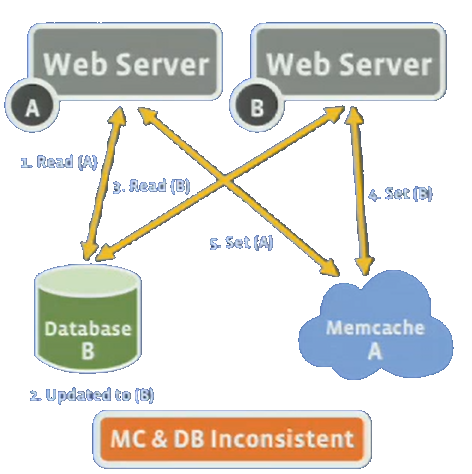
The first step was to implement a front-end cluster with web servers and memcache servers. This system used memcache as a demand-fill, look-aside cache. Key challenges addressed at this stage included:
- Handling a read-heavy workload
- Managing wide fan-out of requests
- Dealing with failures
Scaling to Multiple Clusters
As the system grew, Facebook moved to multiple front-end clusters. This introduced new challenges:
- Controlling data replication
- Maintaining data consistency across clusters
To address these issues, Facebook developed systems like McSqueal, which reads database transactions and broadcasts invalidations to all front-end clusters.
Geographic Distribution
The final stage involved scaling to multiple geographic regions. This step was crucial for fault tolerance but introduced new complexities:
- Managing writes in non-master regions
- Ensuring data consistency across geographically distributed databases
Key Innovations
Leases: To prevent stale sets and thundering herds, Facebook extended the memcache protocol with leases.
McRouter: A routing layer that helps manage the distribution of delete operations across clusters, reducing inter-cluster bandwidth and simplifying configuration management.
Remote Markers: A system to handle potential inconsistencies when reading data that might have been updated in a different geographic region.
Lessons Learned
- Push Complexity to the Client: Facebook found that moving complexity to the client-side library improved scalability and operational efficiency.
- Operational Efficiency is as Important as Performance: Sometimes, a slightly less performant solution can be preferable if it significantly improves operational efficiency.
- Separate Cache and Persistent Store: This separation allows for independent scaling of read rates and storage capacity.
Key Concepts
Memcache/Memcached: An open-source, distributed memory caching system used to speed up dynamic web applications by reducing database load.
Look-aside Cache: A caching strategy where the application checks the cache first before querying the database.
Consistent Hashing: A technique for distributing data across servers that minimizes remapping when server numbers change.
In-cast Congestion: A network issue occurring when multiple servers simultaneously send data to a single recipient, potentially overwhelming it.
Thundering Herd Problem: When many processes waiting for an event are awakened simultaneously, but only one can handle it, causing unnecessary wake-ups.
Stale Set: When outdated data is written to the cache, causing inconsistencies between cache and primary data store.
Lease (in Memcache context): A Facebook extension to the memcache protocol to prevent stale sets and mitigate thundering herds.
McSqueal: A Facebook system that reads database transactions and broadcasts cache invalidations to all front-end clusters.
McRouter (Memcache Router): A Facebook-developed routing layer managing delete operations across clusters.
Remote Marker: A mechanism to handle potential inconsistencies when reading data possibly updated in a different geographic region.
Front-end Cluster: A collection of web servers and memcache servers handling user requests.
Data Dependency DAG: A graph showing dependencies between data pieces needed to fulfill a user request.
MySQL Replication: The process of copying data from a master MySQL database to replica databases.
High Churn Workload: Data that changes frequently, resulting in short-lived cache entries.
Pool (in Facebook's memcache context): A way of partitioning cached data to apply different strategies based on data characteristics.
Geographically Distributed Data Centers: Facebook's approach to improving fault tolerance by having data centers in different locations worldwide.
Master-Replica Database Setup: A configuration where one database (the master) handles writes, while others (replicas) copy data from the master and handle reads.
Invalidation: The process of marking or removing cached data as no longer valid, usually after an update to the primary data store.
Fan-out: In this context, refers to a single request causing multiple subsequent requests to different servers.
Sliding Window Protocol: A technique used by Facebook to limit the number of outstanding messages, balancing between network congestion and round-trip times.