In distributed systems, replication plays a crucial role in ensuring fault tolerance, scalability, and high availability.
The Goal of Replication
Replication aims to maintain the same state at multiple locations within a distributed system. This state can be:
- Entire files or chunks of files (in distributed file systems)
- Database tables (in distributed databases)
- Application-level or OS-level execution state (associated with virtual machines)
By having the same state available at multiple locations, different nodes can provide the same service, enhancing fault tolerance and scalability.
Benefits of Replication
- Fault Tolerance: If one node fails, the service can continue from a backup replica.
- Disaster Recovery: Replicating VMs to remote data centers helps businesses recover from catastrophic events.
- Improved Scalability: Distributing requests across multiple replicas helps handle increased load.
Replication Models
1. Active Replication
- All nodes are active and can handle read requests.
- For write operations, updates must be propagated to all replicas.
2. Standby (Primary-Backup) Replication
- Only one replica (the primary) serves requests.
- Other replicas are on standby, ready to take over if the primary fails.
- The primary must ensure state changes are updated on standby replicas.
Replication Implementation Techniques
1. State Replication
- Operations modify the state on one replica.
- The modified state is copied to update other replicas.
- Pros: No need to re-execute operations.
- Cons: Large state changes may be difficult to identify and transfer.
2. Replicated State Machine
- The same operations are submitted and executed on all replicas.
- Pros: Only small operation logs need to be transferred.
- Cons: Operations must be re-executed on each replica (requires deterministic execution).
Advanced Replication Techniques
Chain Replication
Chain replication addresses scalability issues in consensus-based replication:
- Replicas are organized in a chain.
- Write requests go to the head of the chain.
- Each replica updates the next in the chain.
- Read requests are served by the tail.
Pros:
- Better leader scalability
- Higher write throughput due to pipelining
- Strong consistency guarantees
Cons:
- Not suitable for read-heavy workloads
- Low efficiency for intermediate nodes
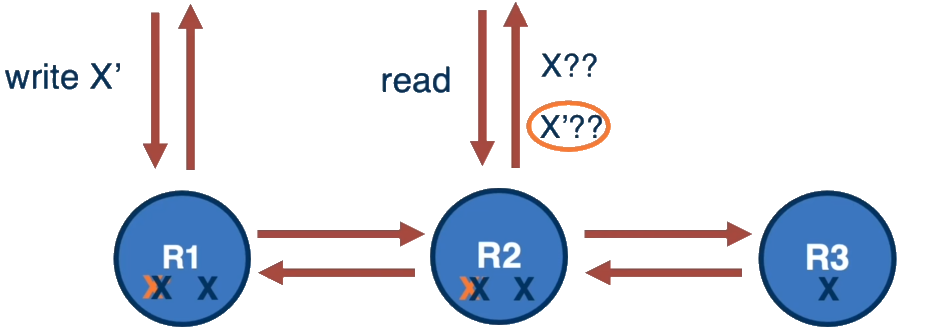
CRAQ (Chain Replication with Apportioned Queries)
CRAQ improves upon chain replication for read-heavy workloads:
- Reads are distributed among all replicas.
- Multiple versions of data are kept at each node.
- Replicas can check with the tail for the latest committed version.
Benefits:
- Significantly higher read throughput compared to basic chain replication
- Scales well with the number of replicas
- Maintains strong consistency
Choosing the Right Replication Technique
Selecting the appropriate replication strategy depends on various factors:
- Workload characteristics (read/write ratio, distribution of operations)
- System configuration (number of nodes, failure rates, network properties)
- Consistency requirements
- Scalability needs
Key Concepts
Replication The process of maintaining the same state at multiple locations in a distributed system.
Fault Tolerance The ability of a system to continue functioning when one or more of its components fail.
Scalability The capability of a system to handle a growing amount of work by adding resources to the system.
Active Replication A replication model where all replicas are active and can handle read requests, with write operations propagated to all replicas.
Standby Replication (Primary-Backup) A replication model where only one replica (the primary) serves requests, while others are on standby to take over if the primary fails.
State Replication A replication implementation technique where modified state is copied directly from one replica to others.
Replicated State Machine A replication implementation technique where the same operations are submitted and executed on all replicas.
Deterministic Execution The property of a system where the same input always produces the same output, regardless of when or where it is executed.
Chain Replication An advanced replication technique where replicas are organized in a chain, with writes propagating from head to tail and reads served by the tail.
CRAQ (Chain Replication with Apportioned Queries) An improvement on chain replication that distributes read operations among all replicas while maintaining strong consistency.
Consistency The property of a distributed system that ensures all nodes see the same data at the same time, or that transactions are executed in a way that yields correct results.
Leader (in replication) The node responsible for coordinating updates in a replicated system, often the primary in standby replication or the head in chain replication.
Replica A copy of data or state maintained in a distributed system for redundancy and improved performance.
Consensus The process of reaching agreement on a single data value or state among distributed processes or systems.
Pipelining A technique used in chain replication where multiple write operations can be in progress simultaneously at different stages of the chain.
Version In CRAQ, a specific state of data at a particular point in time, used to manage concurrent reads and writes.
Workload The amount and type of work that a distributed system is designed to handle, often characterized by the ratio of read to write operations.
Round Trip Time The time it takes for a signal to be sent from a source to a destination and back again, important in measuring network latency in distributed systems.
Review Questions
Contrast active vs. stand-by replication
Active replication:
- All replicas are active and can handle read requests.
- For write operations, updates must be replicated to all other replicas.
Stand-by (or primary backup) replication:
- Only one replica (primary) is active and serves requests.
- Other replicas are on standby.
- When the primary fails, a standby replica takes over.
-
For write operations, the primary must update the state on other replicas.
-
Contrast state vs. log/RSM replication:
Contrast state vs. log/RSM replication
State replication:
- Operations modifying state are executed on one replica.
- Modified state is copied directly to update other replicas.
- Benefit: No need to re-execute operations.
- Drawback: State changes may be large and spread out.
Log/Replicated State Machine (RSM) replication:
- Same operations are submitted and executed on all replicas.
- Only the operation log is propagated, not the modified state.
- Benefit: Smaller updates (just operation logs).
- Drawback: Operations must be re-executed at each location.
- Requires deterministic execution.
What are the problems addressed by chain replication? How are they addressed?
Problems addressed:
- Scalability issues with consensus protocols (e.g., increasing response time with more replicas).
- Leader bottleneck in traditional replication schemes.
How they are addressed:
- Write requests are sent only to the head of the chain.
- Each replica updates only the next one in the chain.
- Read requests are served only by the tail.
- Provides better leader scalability and higher write throughput through pipelining.
- Ensures strong consistency for reads.
What are the problems created by chain replication?
- Low efficiency for read-heavy workloads, as only the tail serves reads.
- Intermediate nodes are underutilized, especially for read-heavy workloads.
How are they addressed in CRAQ (high level)?
How CRAQ (Chain Replication with Apportioned Queries) addresses them:
- Allows reads to be served by all replicas in the chain.
- Maintains multiple versions of data at each node.
- Uses a versioning system to ensure consistency.
-
Improves read throughput by distributing read requests across all replicas.
Can you explain the result from the experimental comparison of CR and CRAQ?
The experiment compared read throughput for different configurations:
- Chain Replication (CR) with 3 replicas
- CRAQ with 3 replicas
- CRAQ with 7 replicas
Results:
- CRAQ consistently delivered higher read throughput than CR.
- At low write loads, CRAQ with 3 replicas achieved almost 3 times higher read throughput compared to CR.
- Even at higher write rates, CRAQ maintained higher read throughput.
- CRAQ scaled well with the number of replicas, showing even higher throughput with 7 replicas.
- CRAQ's throughput decreased slightly as write rates increased due to version management overhead.
Overall, the experiment demonstrated that CRAQ significantly improves read throughput compared to basic chain replication, especially for read-heavy workloads, while maintaining the benefits of chain replication for write operations.