Fault tolerance is a critical aspect of distributed systems design. By understanding the various approaches to checkpointing and logging, developers can create more resilient systems that gracefully handle the inevitable failures that occur in complex, distributed environments.
The goal of fault tolerance is to build a system that can detect, recover from, and continue operating in the face of imperfection.
What are Faults, Errors, and Failures?
Before we jump into recovery techniques, it is crucial to understand the terminology:
- Fault: A defect in the system, such as a hardware malfunction or a software bug.
- Error: The manifestation of a fault, leading to incorrect behavior or information.
- Failure: The ultimate result of an error, causing the system to stop working or produce incorrect results.
Types of Failures
Failures in distributed systems can take various forms:
- Fail-stop: Components stop working entirely.
- Timing failures: Components behave outside of expected timing parameters.
- Omission faults: Actions are missing, such as failing to send or receive messages.
- Arbitrary failures: Components continue to process but produce incorrect results.
Fault Tolerance Techniques
Ideally, we'd love to avoid all failures. However, in the complex world of distributed systems, this is not practical. Instead, we focus on detection and recovery.
Detection
Common detection methods include:
- Heartbeat mechanisms
- Error correction codes
- Checksums
- Cryptographic methods
Recovery
The goal of recovery is to bring the system back to a correct state. Two primary mechanisms facilitate this:
- Checkpointing: Saving the system's state to persistent storage.
- Logging: Recording information about operations that change the system's state.
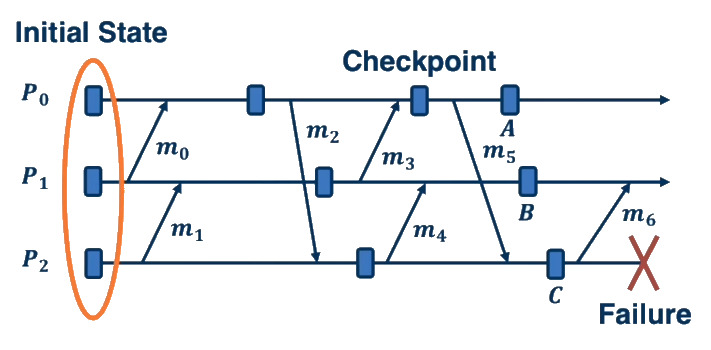
Rollback Recovery
Rollback recovery is a key concept in fault tolerance. When a failure is detected, the system rolls back to a previous, correct state and resumes execution from there. This state must correspond to a consistent cut of the system's execution.
Checkpointing Approaches
- Uncoordinated: Processes take checkpoints independently. Simple but can lead to the "domino effect" during recovery.
- Coordinated: Processes coordinate to ensure checkpoints form a consistent global state. Avoids the domino effect but requires synchronization.
- Communication-induced: Combines independent checkpoints with coordination based on communication patterns.
Logging Approaches
- Pessimistic logging: Logs everything to persistent storage before allowing events to propagate. High overhead but simple recovery.
- Optimistic logging: Assumes logs will be persisted before a failure occurs. Lower overhead but more complex recovery.
Choosing the Right Approach
Selecting the appropriate fault tolerance strategy depends on various factors:
- Workload characteristics
- Failure probabilities
- System architecture
- Communication vs. storage costs
As technology evolves, so do the trade-offs. For instance, new persistent memory technologies are changing the landscape of logging-based approaches.
Key Concepts
Arbitrary Failures: A type of failure where a component continues to process and generate messages, but its behavior is incorrect, either due to malicious reasons or random errors.
Checkpoint: A saved state of a process or entire node, stored in persistent storage, which can be used to rebuild the system state at a specific point in execution.
Consistent Cut: A snapshot of the global state of a distributed system that represents a possible state the system could have been in during execution.
Coordinated Checkpoint: An approach where processes coordinate to take checkpoints simultaneously, ensuring that the checkpoints form part of a consistent global state.
Communication-Induced Checkpoint: A checkpointing approach that combines independent checkpoints with coordination based on communication patterns between processes.
Domino Effect: A problem in uncoordinated checkpointing where rolling back one process forces other processes to roll back, potentially all the way to the initial state of the system.
Error: The manifestation of a fault, leading to incorrect behavior or information in the system.
Fault: A defect in the system, such as a hardware malfunction or a software bug, which may lead to errors and failures.
Failure: The ultimate result of an error, causing the system to stop working or produce incorrect results.
Fault Tolerance: The ability of a system to continue operating correctly in the presence of faults or failures.
Fail-Stop Failure: A type of failure where one or more components of the distributed system stop working and stop responding.
Garbage Collection: In the context of checkpointing, the process of identifying and removing obsolete checkpoints to free up storage space.
Heartbeat Mechanism: A technique used to detect failures by periodically checking whether nodes are responsive.
Intermittent Fault: A fault that manifests itself occasionally.
Logging: A recovery mechanism that involves recording information about operations that change the system's state.
Omission Fault: A type of fault where some actions are missing, such as a node failing to send or receive all expected messages.
Optimistic Logging: A logging approach that assumes logs will be persisted before a failure occurs, allowing for lower overhead but more complex recovery.
Orphaned Events: In the context of logging, these are events that appear to have occurred in one part of the system but have no corresponding cause in another part, typically due to inconsistent recovery.
Permanent Fault: A fault that, once activated, persists until it is fixed or removed.
Pessimistic Logging: A logging approach that writes everything to persistent storage before allowing events to propagate, resulting in high overhead but simple recovery.
Recovery: The process of bringing a system back to a correct state after a failure has occurred.
Rollback: The process of returning the system to a previous state, typically one known to be correct, as part of the recovery process.
Rollback Recovery: A fault tolerance technique that involves rolling back to a previous correct state and then resuming execution from that point.
Timing Failure: A type of failure where system components behave outside of expected timing parameters.
Transient Fault: A fault that manifests itself only once and then disappears.
Uncoordinated Checkpoint: An approach where processes take checkpoints independently, without coordination with other processes.
Review Questions
What is the main idea of rollback-recovery as a FT technique?
The main idea of rollback-recovery as a fault tolerance technique is to allow a system to recover from failures by rolling back to a previous consistent state and then resuming execution from that point. This involves:
- Detecting failures in the system
- Rolling back to a previous state known to be correct (typically a consistent cut in the system's execution)
- Removing the effects of any operations or messages that occurred after the rollback point
- Resuming correct execution from the rollback point
The goal is to achieve fault tolerance by enabling the system to recover from failures and continue execution, even in the presence of faults.
What are the differences and tradeoffs of checkpointing vs. logging as a FT technique?
Checkpointing:
- Saves the entire state of the system/process to persistent storage
- Requires more I/O during normal operation
- Faster recovery as the state can be directly loaded
- May lose work done between checkpoints
Logging:
- Records information about operations that change the system state
- Less I/O during normal operation
- Slower recovery as the log must be replayed
- Can potentially recover more recent state
What are all the different metrics to think about when comparing the two?
Metrics to consider when comparing:
- I/O overhead during normal operation
- Storage requirements
- Recovery time
- Potential data loss
- Impact on system performance
- Scalability with system size
- Complexity of implementation
- Flexibility in handling different types of failures
- Ability to handle concurrent operations
- Consistency guarantees
- Adaptability to different workload patterns
Describe and explain the pros/cons/tradeoffs of coordinated, uncoordinated, communication-induced checkpointing.
Uncoordinated Checkpointing
Pros:
- Simple implementation
- Nodes can checkpoint independently
Cons:
- Risk of domino effect during recovery
- May create many useless checkpoints
- Requires maintaining multiple checkpoints per process
- Complex garbage collection needed
- Potentially excessive storage requirements
Coordinated Checkpointing
Pros:
- No domino effect
- Only one checkpoint per process needed
- Simple garbage collection
- Guaranteed consistent recovery line
Cons:
- Requires global coordination
- May lead to unnecessary checkpoints for some processes
- Blocking nature during coordination
Communication-Induced Checkpointing
Pros:
- Non-blocking
- Reduces unnecessary checkpoints
- Ensures consistent recovery line
Cons:
- More complex implementation
- May still create some unnecessary checkpoints
-
Requires piggybacking checkpoint information on messages
Reason through examples of how changes in factors would impact the choice of FT technique
We mention a number of factors which influence the choice of a FT technique. Can you reason through some examples, say considering change in storage cost, or system scale, or read/write ratio of the workload, and whether or how those changes would impact the winner among any two of the techniques we discussed?
Decreasing storage costs
If storage costs decrease significantly, techniques that rely heavily on storage (like pessimistic logging or frequent checkpointing) become more attractive. This might make pessimistic logging more favorable compared to optimistic logging, as the main drawback of immediate persistent storage updates becomes less significant.
Increasing system scale
As systems grow larger, coordinated checkpointing becomes less practical due to the increasing overhead of global coordination. In this case, communication-induced checkpointing or optimistic logging might become more attractive as they do not require global coordination and can scale better with system size.
Changing read/write ratio of the workload
For a workload with a high read-to-write ratio, logging-based approaches might be more efficient than frequent checkpointing. This is because logging only needs to record write operations, which are less frequent in this scenario. Optimistic logging might be particularly effective here, as it allows for faster read operations without immediate persistence requirements.
Improved network speed and reliability
With faster and more reliable networks, the overhead of coordinated checkpointing decreases, potentially making it more attractive compared to uncoordinated approaches. Additionally, causality tracking in optimistic logging becomes more efficient, potentially making it a stronger competitor to pessimistic logging.
Summary
These examples illustrate how changes in system characteristics, workload patterns, and technology can influence the choice of fault tolerance technique. The optimal choice depends on a careful analysis of these factors in the specific context of the system being designed.